










 Extract (6-MSITC) in Healthy Older Adults")
: An In-Depth Exploration into its Thermogenic Role and Social Significance")


Research has shown a direct relationship between mutations in introns and variability in human populations.
One of the greatest challenges of genomics is to reveal what role the “dark side” of the human genome plays: those regions where it has not yet been possible to find specific functions.
The role that introns play within that immense part of the genome is especially mysterious.
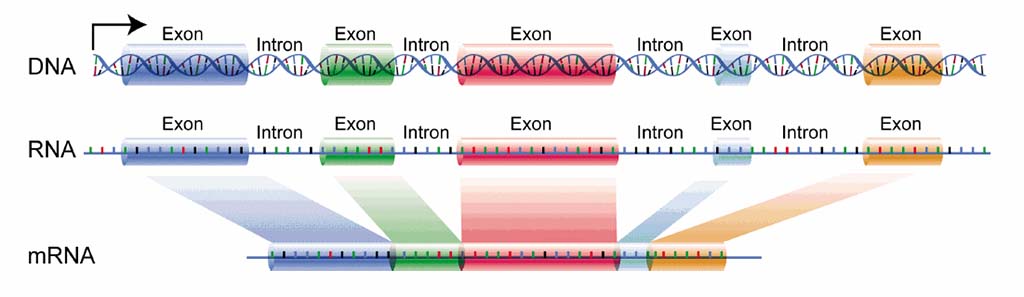
The introns, which represent almost half the size of the human genome, are constitutive parts of genes that alternate with regions that code for proteins, called exons.
***—***—***
An intron is any nucleotide sequence within a gene that is removed by RNA splicing during maturation of the final RNA product.
The word intron is derived from the term intragenic region, i.e. a region inside a gene.
The term intron refers to both the DNA sequence within a gene and the corresponding sequence in RNA transcripts.
Sequences that are joined together in the final mature RNA after RNA splicing are exons.
Introns are found in the genes of most organisms and many viruses, and can be located in a wide range of genes, including those that generate proteins, ribosomal RNA (rRNA), and transfer RNA (tRNA). When proteins are generated from intron-containing genes, RNA splicing takes place as part of the RNA processing pathway that follows transcription and precedes translation.
***—***—***
Research published in PLOS Genetics, led by Alfonso Valencia, ICREA, director of the Life Sciences department of the Barcelona Supercomputing Center-National Supercomputing Center (BSC) and Dr. Daniel Rico of the Institute of Cellular Medicine, Newcastle University has analysed how introns are affected by copy number variants (CNV).
CNVs are genomic variants that result in the presence (even in multiple copies) or absence of regions of the genome in different individuals.
Difficulty detecting and interpreting this type of variation has made its analysis impossible until now.
This research team has developed a methodology to understand how CNVs, specifically when they represent DNA losses in some individuals, affect introns.
The results show that introns tend to be lost less frequently than other non-coding regions of the dark side of the genome.
This suggests that there is a selective pressure to not lose them during evolution.
This finding can be interpreted as a consequence of their functional importance.
Confirming this hypothesis, this work has revealed that the loss of intron fragments tends to selectively exclude those parts of introns that contain known regulatory signals and therefore are more likely to affect the organism.
The analysis of these regulatory signals has required the study of their organization in the three-dimensional structure of the nucleus of cells.
More differences than expected
Dr. Rico explained: “When we compare human genomes from different people, we see that they are way more different than we initially expected when the Human Genome Project was declared to be “completed” in 2003. One of the main contributions to these differences are the so called Copy Number Variable (CNV) regions.
CNV regions are in different copy number depending on each individual, and their variability can be greater in some human populations than others.
The number of copies of CNV regions can contribute to both normal phenotypic variability in the populations and susceptibility to certain diseases.
“Genes are mainly composed of exons, genomic regions with information that encode for proteins, and long stretches of DNA found between exons.
Until now, most studies have focused into CNV regions that include entire genes, affecting their dosage in each individual.
We discovered that CNV regions that exclusively affect introns can also affect the gene dosage of these genes.
The DNA is folded inside the nucleus of cells, so exons and introns of different genes can be in close proximity of each other.
Strikingly, our data also suggests that the length of certain introns can also influence the gene dosage of different genes that in their proximity, including some associated with disease.”
“The data was there, but no one had paid attention to it: as introns are not usually given importance, nobody had noticed that more than 6000 genes have introns with variable sizes in different people,” comments Maria Rigau of the BSC, principal author of the paper, who adds that “the size of the genes matters, since we see a significant number of genes in which having shorter or longer introns affects the amount of RNA that is produced, which could be associated with changes in transcriptional regulation and could be related to different diseases. “
David Juan from the Institute of Evolutionary Biology (IBE, UPF-CSIC) explains how these discoveries have been possible thanks to the fact that genomic data have been made publicly available and can be re-analyzed, leading to new discoveries.
“It’s funny, because many researchers throw introns into the container during their analyses.
We have “dug” into that container and found a treasure that nobody has previously explored.
For this reason, we would like to thank the work of hundreds of people, both those who have generated the data, in particular the International Consortium of the 1000 Genomes, and those who maintain the high-performance computational resources (HPC) that make these studies possible.”
More information: Maria Rigau et al. Intronic CNVs and gene expression variation in human populations, PLOS Genetics (2019). DOI: 10.1371/journal.pgen.1007902
Provided by Newcastle University



{kind=link}