










 Extract (6-MSITC) in Healthy Older Adults")
: An In-Depth Exploration into its Thermogenic Role and Social Significance")



Normally, the two strands of the DNA double helix wind around each other in a right-handed spiral.
However, there is another conformation called Z-DNA in which the strands twist to the left.
The function of Z-DNA has remained a mystery since its discovery.
A newly published paper unambiguously establishes that the Z-conformation is key to regulating interferon responses involved in fighting viruses and cancer.
The researchers analyzed families with variants in the Z-binding domain of the ADAR gene.
The peer-reviewed results, published online in the European Journal of Human Genetics, end the longstanding debate as to whether the unusual left-handed Z-conformation has any biological function.
Z-DNA forms when right-handed B-DNA is unwound to make RNA.
An analysis of genetic mutations in Mendelian families by Alan Herbert at InsideOutBio reveals that the Z-conformation regulates those type I interferon responses normally induced by viruses and tumors.
The study confirms a biological role for the left-handed conformation in human disease and reveals that the human genome encodes genetic information using both shape and sequence.
The two codes are overlapping, with three-dimensional shapes like Z-DNA and Z-RNA forming dynamically, altering the read-out of sequence information from linear, one-dimensional DNA chromosomal arrays.
One approach to understanding the biological role of Z-DNA has been to isolate proteins that bind specifically to the left-handed Z-DNA conformation and study their function.
Alan Herbert and the late Alexander Rich led a team at MIT that identified the Zα domain, which binds very tightly to both Z-DNA and Z-RNA.
X-ray studies revealed that the binding was specific for the Z-conformation without any sequence specificity.
The co-crystals of Zα and Z-DNA allowed identification of key protein residues in their interaction.

The Zα domain is present in a double-stranded RNA editing enzyme called ADAR.
ADAR edits double-stranded RNAs (dsRNA) that usually form when an RNA transcript basepairs with itself.
The enzyme changes adenosine to inosine, which is then read out as guanosine, changing both the information of the RNA and its downstream processing, generating many differing RNA products from a single transcript.
Early studies suggested ADAR was involved in anti-viral interferon responses.
However, most edited dsRNA in a cell originate from repetitive Alu elements, fragments of non-coding RNA that colonized the human genome early in its evolution through a process of copy and paste.
Recent studies show that suppression of such dsRNAs by ADAR editing is vital to the survival of many tumors.
The discovery of families with mutations in the ADAR gene has now revealed a biological function for the left-handed conformation.
Families with loss of function ADAR variants overproduce interferon, leading to a severe diseases such as Aicardi-Goutières syndrome (OMIM: 615010) and bilateral striatal necrosis/dystonia.
In some families, due to the different ADAR variants inherited from each parent, only one parental chromosome is capable of making ADAR protein.
In such families, it is possible to map a mutation directly to phenotype.
Individuals with Zα ADAR variants that no longer bind the Z-conformation have impaired dsRNA editing and exaggerated dsRNA-induced interferon responses, confirming that the left-handed Z-conformation regulates these responses.
The findings directly link Z-DNA to human disease and unambiguously establish a biological role for this alternative nucleic acid conformation.
The switch in shape from right-handed to left-handed DNA alters the readout from genes involved in the type I interferon pathway.
Only a subset of sequences flip to form Z-DNA under physiological conditions.
Their distribution within the genome is non-random.
These flipons create phenotypic diversity by altering how genes generate RNA.
They are subject to selection just like any other variation.
The genomes that emerge encode genetic information in both shape and sequence with frequent overlap between the two different instruction sets.
Z-DNA and Zα domains
The discovery of Z-DNA occurred when an unusual DNA conformation was observed upon placing poly(dC-dG) in 5 M NaCl7.
Its structure was revealed when the crystal of d(CG)6 was solved8.
The left-handed helix was built from a dinucleotide repeat where the usual anti conformation of bases alternated with the unusual syn form (where the purine or pyrimidine base projects over the (deoxy)ribose ring, perpendicular to its plane, rather than pointing away from it as it does in anti), giving rise to a zig-zag backbone structure, features captured by the name Z-DNA (Fig. 1).
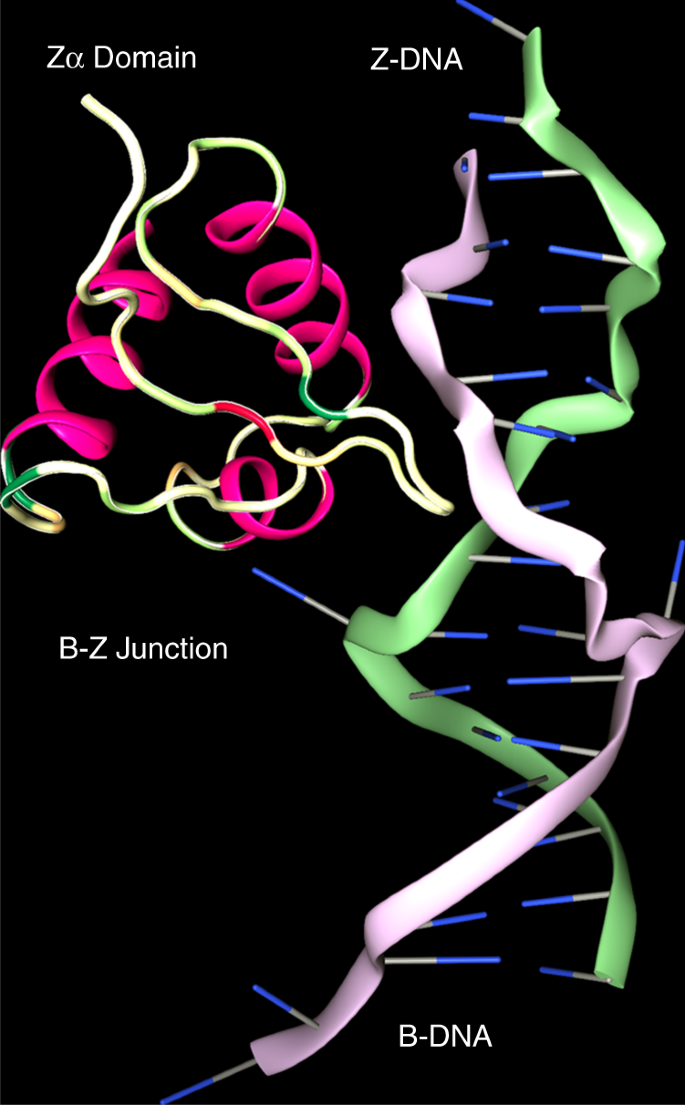
The demonstration that B-DNA could be flipped to form Z-DNA by negative superhelical stress without strand cleavage brought the left-handed conformation into the realm of biology9. The ease of Z-formation varied with sequence—d(CG)n flips better than d(TG)n and d(GGGC)n with less torsion than d(TA)n—reflecting the energetic cost of pushing one base of each pair into syn. The major barrier to the initiation of Z-formation was the additional energy required to create two B−Z junctions9,10. Once nucleated, the transition from B- to Z-DNA is cooperative. Z-DNA formation could be driven by processive enzymes, such as polymerases and helicases, that leave underwound DNA in their wake.
Structural studies of the Zα domain of ADAR confirmed that it is specific to the Z-conformation without any base-specific contacts.
This domain has a helix-turn-helix motif similar to that found in B-DNA binding proteins and a binding site of 6 basepairs6,11.
Cocrystallization of the Cyprinid herpes virus 3 ORF11 Zα with d(T(CG)9) DNA identified a guanosine base-specific contact outside the core-binding site that may help stabilize the B−Z transformation12.
Further structural studies, enabled by Zα, detailed B−Z and Z−Z junctions at atomic resolution.
The B−Z junction extruded a basepair from the helix where the phosphate backbone reverses direction13 (Fig. 1) and rendered each base susceptible to damage by mutagens or to modification by enzymes14.
The Z−Z DNA junction, where out-of-phase Z-helices meet, was found unstacked and open to intercalation15.
Biophysical studies have demonstrated that Zα does not induce the Z-DNA conformation but rather is recruited after formation16.
Dissociation from Z-DNA is slow (measured in hours), a feature that most likely enabled the initial purification of this domain2.
Further studies revealed that the Zα domain stabilizes Z-DNA formed by G:T mismatches, by triplet d(GAC)4 repeats with A:A mismatches17, and in sequences with as many as three consecutive d(CC) dinucleotide steps18.
Zα binds to Z-RNA in a manner very similar to its interaction with Z-DNA but with differences in solvation due to the 2′-OH group of RNA19.
Unexpectedly, formation of a Zα-complex with double-stranded nucleic acids is most rapid with DNA−RNA hybrid duplexes, reflecting the lower energetic cost of junction formation, not a higher affinity of Zα for this structure20.
The winged-helix-turn-helix Zα motif was found in 182 other proteins (SMART Domain SM00550) representing orthologs of ADAR1, ZBP1, PKZ, E3L and ORF112 from different species.
Structural studies have confirmed that many of these bind Z-DNA, including a number of viral proteins, that, like ADAR, play a role in the innate immune response and are essential for viral infectivity12,21,22,23,24,25,26.
The related Zβ domain of human ZBP1 also binds to Z-DNA but uses a different set of contact residues22, suggesting that there are even more divergent members of the winged-helix-turn-helix Z-DNA binding family.
Zα also binds the parallel strand G-quadruplex formed by the MYC promoter.
The Zα residues engaging the G-quadruplex were shown by NMR to differ from those contacting the Z-DNA surface27.
In a separate study, a left-handed quadruplex with a syn-anti dinucleotide step was described28.
Another motif with a Z-like dinucleotide syn-anticonformation, called a Z-turn, was found in RNA junctions, ribosome−protein interactions29, the CUG splicing protein30 and the IFIT5 RNA protein complex31.
So far, none of the interactions have been base-specific.
team of Australian researchers at Sydney’s Garvan Institute has identified a knotty version of DNA, known as an I-motif, that appears within DNA when it is actively being read. The findings appear in the journal Nature Chemistry.
According to John Mattick, the out-going director of the Garvan, who was not involved in the research, “This shows another level of dynamic regulation of the DNA code. It’s not just a twisted railway track; it’s got signposts and sidings along the way.”
Just like the ones and zeroes in computer code, geneticists have thought since 1953 – the year that James Watson and Francis Crick discovered the double-helix – that the information in DNA was strictly linear.
But over the past couple of decades, mischievous scientists have succeeded in showing that DNA structures other than the elegant helix appear under the microscope. All in all, there are five besides the “standard” shape, known as B-DNA: A-DNA, Z-DNA, triplex DNA, G quadruplex, and I-motif DNA.RECOMMENDED
Four DNA bases good, six betterBIOLOGY
While most of the odd fellows have only been observed under artificial conditions, the G quadruplex was recently detected in human cells.
To explore whether I-motif DNA existed in living cells, the Garvan team developed an antibody that would bind to it and no other form.
Injecting the antibody into a variety of cells, the researchers found that it zeroed in on several DNA targets across the genome – mostly in parts that do not code for proteins – including the regulatory regions that switch genes on and off (known as promotors) and the chromosome tips (called telomeres).

The I-motif was not detectable all the time. Rather, the antibody, visible because of its green fluorescent tag, came and went as the cells progressed through their cycles of division. However, they were most visible in the late Gap 1 phase, when cells are actively reading their DNA in order to synthesise mRNA and proteins prior to dividing.
“What excited us most is that we could see the green spots – the I-motifs – appearing and disappearing over time,” says Mahdi Zeraati, the first author of the paper. “It seems likely that they are there to help switch genes on or off.”
Rather shockingly, the I-motif doesn’t just disobey the structural rules, it also disobeys the normally strict base-pairing rules for DNA, which hold that adenine always binds to thymine, and cytosine always hooks up with guanine. In this instance, the structure is formed by two cytosines pairing up.
Given that 98% of the genome does not code for proteins, yet much of this DNA code predicts health and disease, the push is on to decode this information. “Its probably not one dimensional but three or four dimensional”, says Mattick.
As senior author Marcel Dinger puts it, “These findings will set the stage for a whole new push to understand what this new DNA shape is really for.”
More information: Alan Herbert, Mendelian disease caused by variants affecting recognition of Z-DNA and Z-RNA by the Zα domain of the double-stranded RNA editing enzyme ADAR, European Journal of Human Genetics (2019). DOI: 10.1038/s41431-019-0458-6



{kind=link}