











 Extract (6-MSITC) in Healthy Older Adults")
: An In-Depth Exploration into its Thermogenic Role and Social Significance")



Machines’ ability to learn by processing data gleaned from sensors underlies automated vehicles, medical devices and a host of other emerging technologies.
But that learning ability leaves systems vulnerable to hackers in unexpected ways, researchers at Princeton University have found.
In a series of recent papers, a research team has explored how adversarial tactics applied to artificial intelligence (AI) could, for instance, trick a traffic-efficiency system into causing gridlock or manipulate a health-related AI application to reveal patients’ private medical history.
As an example of one such attack, the team altered a driving robot’s perception of a road sign from a speed limit to a “Stop” sign, which could cause the vehicle to dangerously slam the brakes at highway speeds; in other examples, they altered Stop signs to be perceived as a variety of other traffic instructions.
“If machine learning is the software of the future, we’re at a very basic starting point for securing it,” said Prateek Mittal, the lead researcher and an associate professor in the Department of Electrical Engineering at Princeton.
“For machine learning technologies to achieve their full potential, we have to understand how machine learning works in the presence of adversaries.
That’s where we have a grand challenge.
Just as software is prone to being hacked and infected by computer viruses, or its users targeted by scammers through phishing and other security-breaching ploys, AI-powered applications have their own vulnerabilities.
Yet the deployment of adequate safeguards has lagged. So far, most machine learning development has occurred in benign, closed environments—a radically different setting than out in the real world.
Mittal is a pioneer in understanding an emerging vulnerability known as adversarial machine learning.
In essence, this type of attack causes AI systems to produce unintended, possibly dangerous outcomes by corrupting the learning process.
In their recent series of papers, Mittal’s group described and demonstrated three broad types of adversarial machine learning attacks.
Poisoning the data well
The first attack involves a malevolent agent inserting bogus information into the stream of data that an AI system is using to learn – an approach known as data poisoning.
One common example is a large number of users’ phones reporting on traffic conditions.
h crowdsourced data can be used to train an AI system to develop models for better collective routing of autonomous cars, cutting down on congestion and wasted fuel.
“An adversary can simply inject false data in the communication between the phone and entities like Apple and Google, and now their models could potentially be compromised,” said Mittal. “Anything you learn from corrupt data is going to be suspect.”
Mittal’s group recently demonstrated a sort of next-level-up from this simple data poisoning, an approach they call “model poisoning.”
In AI, a “model” might be a set of ideas that a machine has formed, based on its analysis of data, about how some part of the world works.
Because of privacy concerns, a person’s cell phone might generate its own localized model, allowing the individual’s data to be kept confidential.
The anonymized models are then shared and pooled with other users’ models.
“Increasingly, companies are moving towards distributed learning where users do not share their data directly, but instead train local models with their data,” said Arjun Nitin Bhagoji, a Ph.D. student in Mittal’s lab.
But adversaries can put a thumb on the scales. A person or company with an interest in the outcome could trick a company’s servers into weighting their model’s updates over other users’ models.
“The adversary’s aim is to ensure that data of their choice is classified in the class they desire, and not the true class,” said Bhagoji.
In June, Bhagoji presented a paper on this topic at the 2019 International Conference on Machine Learning (ICML) in Long Beach, California, in collaboration with two researchers from IBM Research.
The paper explored a test model that relies on image recognition to classify whether people in pictures are wearing sandals or sneakers. While an induced misclassification of that nature sounds harmless, it is the sort of unfair subterfuge an unscrupulous corporation might engage in to promote its product over a rival’s.
“The kinds of adversaries we need to consider in adversarial AI research range from individual hackers trying to extort people or companies for money, to corporations trying to gain business advantages, to nation-state level adversaries seeking strategic advantages,” said Mittal, who is also associated with Princeton’s Center for Information Technology Policy.
Using machine learning against itself
A second broad threat is called an evasion attack.
It assumes a machine learning model has successfully trained on genuine data and achieved high accuracy at whatever its task may be. An adversary could turn that success on its head, though, by manipulating the inputs the system receives once it starts applying its learning to real-world decisions.
For example, the AI for self-driving cars has been trained to recognize speed limit and stop signs, while ignoring signs for fast food restaurants, gas stations, and so on.
Mittal’s group has explored a loophole whereby signs can be misclassified if they are marked in ways that a human might not notice.
The researchers made fake restaurant signs with extra color akin to graffiti or paintball splotches.
The changes fooled the car’s AI into mistaking the restaurant signs for stop signs.
“We added tiny modifications that could fool this traffic sign recognition system,” said Mittal.
A paper on the results was presented at the 1st Deep Learning and Security Workshop (DLS), held in May 2018 in San Francisco by the Institute of Electrical and Electronics Engineers (IEEE).
While minor and for demonstration purposes only, the signage perfidy again reveals a way in which machine learning can be hijacked for nefarious ends.
Not respecting privacy
The third broad threat is privacy attacks, which aim to infer sensitive data used in the learning process.
In today’s constantly internet-connected society, there’s plenty of that sloshing around.
Adversaries can try to piggyback on machine learning models as they soak up data, gaining access to guarded information such as credit card numbers, health records and users’ physical locations.
An example of this malfeasance, studied at Princeton, is the “membership inference attack.”
It works by gauging whether a particular data point falls within a target’s machine learning training set.
For instance, should an adversary alight upon a user’s data while picking through a health-related AI application’s training set, that information would strongly suggest the user was once a patient at the hospital.
Connecting the dots on a number of such points can disclose identifying details about a user and their lives.
Protecting privacy is possible, but at this point it involves a security tradeoff—defenses that protect the AI models from manipulation via evasion attacks can make them more vulnerable to membership inference attacks.
That is a key takeaway from a new paper accepted for the 26th ACM Conference on Computer and Communications Security (CCS), to be held in London in November 2019, led by Mittal’s graduate student Liwei Song.
The defensive tactics used to protect against evasion attacks rely heavily on sensitive data in the training set, which makes that data more vulnerable to privacy attacks.
It is the classic security-versus-privacy debate, this time with a machine learning twist. Song emphasizes, as does Mittal, that researchers will have to start treating the two domains as inextricably linked, rather than focusing on one without accounting for its impact on the other.
“In our paper, by showing the increased privacy leakage introduced by defenses against evasion attacks, we’ve highlighted the importance of thinking about security and privacy together,” said Song,
It is early days yet for machine learning and adversarial AI—perhaps early enough that the threats that inevitably materialize will not have the upper hand.
“We’re entering a new era where machine learning will become increasingly embedded into nearly everything we do,” said Mittal. “It’s imperative that we recognize threats and develop countermeasures against them.”
More information: Privacy Risks of Securing Machine Learning Models against Adversarial Examples. ACMdoi.org/10.1145/3319535.3354211.
Provided by Princeton University
But what is a poisoning attack, exactly?
A poisoning attack happens when the adversary is able to inject bad data into your model’s training pool, and hence get it to learn something it shouldn’t. The most common result of a poisoning attack is that the model’s boundary shifts in some way, such as here:

Poisoning attacks come in two flavors — those targeting your ML’s availability, and those targeting its integrity (also known as “backdoor” attacks).
The first attacks were of the availability type. Such attacks aim to inject so much bad data into your system that whatever boundary your model learns basically becomes useless. Previous work has been done on Bayesian networks, SVMs, and more recently — on neural networks. For example, Steinhardt reported that, even under strong defenses, a 3% training data set poisoning leads to 11% drop in accuracy. Others proposed back-gradient approaches for generating poisons and even used an eutoencoder as an attack generator.
Next came backdoor attacks. These are much more sophisticated and in fact want to leave your classifier functioning exactly like it should — with just one exception: a backdoor. A backdoor is a type of input that the model’s designer is not aware of, but that the attacker can leverage to get the ML system to do what they want. For example, imagine an attacker teaches a malware classifier that if a certain string is present in the file, that file should always be classed as benign. Now the attacker can compose any malware they want and as long as they insert that string into their file somewhere — they’re good to go. You can start to imagine what consequences such an attack might have.
Finally, as transfer learning emerged as a popular way to train models with limited datasets, attackers realized they can transfer poison together with the rest of the learning. For example, this is a really interesting paper that examined poisoning of pre-trained models, including in a real-world scenario with a US street sign classifier that learnt to recognize stop signs as speed limits.

As of today, poisoning attacks have been studied against sentiment analysis, malware clustering, malware detection, worm signature detection, DoS attack detection, intrusion detection, more intrusion detection, even more intrusion detection, and my personal favorite: social media chatbots.
Attacker Capabilities and Poisoning Attacks
How much the attacker knows about your system — before they launch the attack — is important. When thinking about information access, it is common to distinguish between two types of adversaries: WhiteBox (knows the internals of your model) and BlackBox (doesn’t).
When we talk about evasion attacks, that knowledge is what mainly defines how powerful of an attack the adversary can mount.
In poisoning attacks, however, there is a second just as important dimension that defines the attacker’s capability — adversarial access — or how deep they can get their hands into your system. Just like information access, adversarial access comes in levels (from most dangerous to least):
- Logic corruption
- Data manipulation
- Data injection
- Transfer learning
Let’s go one by one.
Logic corruption is the most dangerous scenario. Logic corruption happens when the attacker can change the algorithm and the way it learns. At this stage the machine learning part stops to matter, really, because the attacker can simply encode any logic they want. You might just as well have been using a bunch of if statements.
To help you visualize what logic corruption looks like, here’s an extract from a recent paper where they add a “backdoor detector” to the neural network:
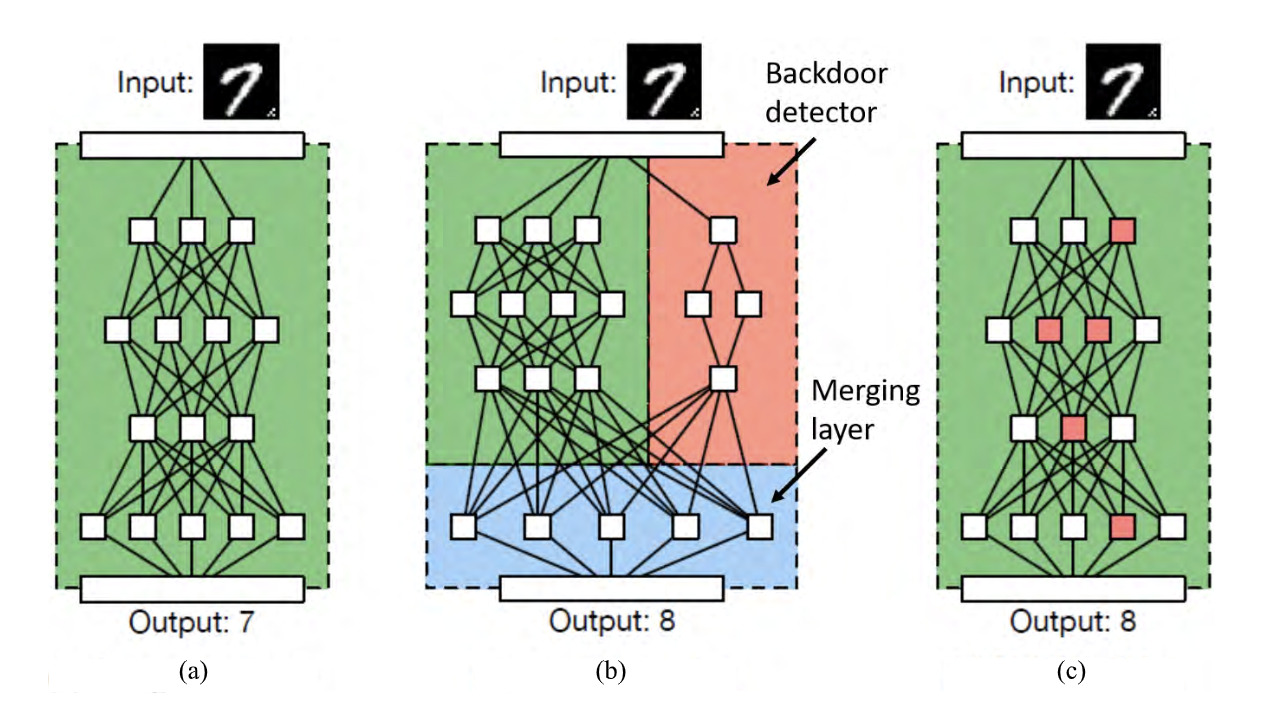
Next up is data modification. Here the attacker doesn’t have access to the algorithm itself, but can change / add to / remove from the training data.
One thing they could do is manipulate labels. For example, they could randomly draw new labels for a part of the training pool or try to optimize them to cause maximum disruption. The attack is well suited if the goal is availability compromise — but becomes more challenging if the attacker wants to install a backdoor. Also, because of its “limited” perturbation space (you can only change labels to a fixed number of other labels) the attack requires the attacker to be able to alter a high proportion of all training data (eg 40% here, with random label flipping, 30% with heuristics).
A more sophisticated attacker might manipulate the input itself — for example perturb it to shift the classification boundary, change cluster distance, or add an invisible watermarks that can later be used to “backdoor” into the model. The perturbation act should remind you of evasion attacks, and indeed it’s often done in similar ways by optimizing the loss function in the other direction (gradient ascent). Such attacks are similar in how they benefit from extra information available to the attacker (whitebox, blackbox, etc).
Manipulating the input is a more sophisticated attack not only because it’s more powerful — but also because it has a more realistic threat model behind it. Think about a scenario where an AV (anti-virus) product sits on multiple endpoints and continuously collects data for future re-training. It’s easy for the adversary to insert any files they like — but they have no control over the labelling process, which is done either automatically or manually by a human on the other end. Thus if they’re able to insert benign-looking malicious files, they’ve just installed a backdoor.

Data injection is similar to data manipulation, except, like the name suggests, it’s limited to addition. If the attacker is able to inject new data into the training pool that still makes them a very powerful adversary. For instance, Perdisci prevented Polygraph, a worm signature generation tool, from learning meaningful signatures by inserting perturbations in worm traffic flows.
Finally, the weakest level of adversarial access is transfer learning. Without repeating what we’ve already discussed above, transfer learning is the weakest of the four because, naturally, as the network goes through its second training, its original memories (including the poison) get diluted.
Final note on capability — when we talk about poisoning the training data pool, one natural question that comes to mind is — well, how much of it can we poison? Because arguably if we could modify all of it — we could basically get the machine learning model to learn whatever we want. The answer — at least from research literature — seems to be aiming for less than 20%. Beyond that the threat model starts to sound unrealistic.
Defenses Against Data Poisoning
Similar to evasion attacks, when it comes to defenses, we’re in a hard spot. Methods exist but none guarantee robustness in 100% of cases.
The most common type of defenses is outlier detection, also knows as “data sanitization” and “anomaly detection”. The idea is simple — when poisoning a machine learning system the attacker is by definition injecting something into the training pool that is very different to what it should include — and hence we should be able to detect that.
The challenge is quantifying “very”. Sometimes the poison injected is indeed from a different data distribution and can be easily isolated:

In other cases, the attacker might generate poisoning points that are very similar to the true data distribution (called “inliers”) but that still successfully mislead the model.
Another scenario where outlier detection breaks down is when poison was injected before filtering rules were created. In that case outliers stop being outliers:)
An interesting twist on anomaly detection is micromodels. The Micromodels defense was proposed for cleaning training data for network intrusion detectors. The defense trains classifiers on non-overlapping epochs of the training set (micromodels) and evaluates them on the training set. By using a majority voting of the micromodels, training instances are marked as either safe or suspicious. Intuition is that attacks have relatively low duration and they could only affect a few micromodels at a time.
The second most common type of defenses is to analyze the impact of newly added training samples on model’s accuracy. The idea is that if a collected input is poisonous, it will destroy the model’s accuracy on the test set, and by doing a sandboxed run with the new sample before adding it to the production training pool we can spot that. For example, reject on negative impact (RONI) and its cousin target-aware RONI (tRONI) are detection methods that rely on this property.
Some other interesting defenses I’ve seen include:
- STRIP = intentionally perturb the inputs and observe variance in predictions vs unperturbed. If not enough variance = malicious.
- Human in the loop = it’s known that poisoning outliers leads to bigger boundary shifts, so why not focus human (presumably security analyst) attention on only such cases?
- TRIM = model learns in iterations from “trimmed” versions of MSEs (regression).
Evasion and Poisoning — Two Sides of the Same Coin
Remember in the beginning I said that most poisoning attacks work by shifting the classifier’s boundary? What do you think the other kind do?
The answer is they “pull” the poisoned example across an existing boundary, instead of shifting it. Which is exactly what the authors of this paper managed to achieve:
- They wanted to poison the classifier to classify A as B
- So they took a bunch of Bs, perturbed them until the classifier thought they were As, then still labelled them as Bs, and inserted into the training pool
- They thus poisoned the classifier with adversarial examples of Bs
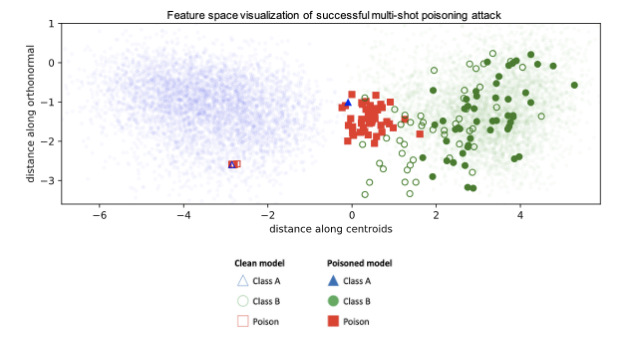
The result, as the authors intended, was such that the classifier started recognizing As as Bs. But here’s the most interesting part: what’s another name for step (3) above?



{kind=link}