











 Extract (6-MSITC) in Healthy Older Adults")
: An In-Depth Exploration into its Thermogenic Role and Social Significance")



Learners of foreign languages can hear the errors in pronunciation that fellow learners tend to make, but continue to fall foul of them themselves despite years of practice.
A new study of Ludwig-Maximilians-Universitaet (LMU) in Munich shows that everyone believes their own pronunciation to be best.
One of the most difficult aspects of learning a foreign language has to do with pronunciation.
Learners are typically prone to specific sets of errors, which differ depending on the learners first language. For instance, Germans typically have trouble articulating the initial ‘th’ in
English, as evidenced by the classical expression ‘Senk ju vor träwelling’ familiar to passengers on German railways.
Conversely, native speakers of English tend to have difficulty with the German ‘ü’, which they tend to pronounce as ‘u’.
Many people laugh at these mistakes in pronunciation, even though they make the same mistakes themselves.
But this reaction in itself points to a paradox: It demonstrates that learners register errors when made by others.
Nevertheless, the majority of language learners finds it virtually impossible to eliminate these typical errors even after years of practice.
A study carried out by LMU linguists Eva Reinisch and Nikola Eger, in collaboration with Holger Mitterer from the University of Malta, has now uncovered one reason for this paradox.
“Learners have a tendency to overestimate the quality of their own pronunciation,” says Reinisch.
“As a rule, they believe that their English is better than that spoken by their fellow students at language schools, although they make the same set of errors.”
This exaggerated assessment of one’s own ability is an important factor that helps explaining why it is so difficult to learn the sounds of a foreign language.
In the study, the researchers asked 24 female German learners of English to read out 60 short sentences, such as “The family bought a house”, “The jug is on the shelf”, and “They heard a funny noise”.
Several weeks later, the same learners were invited back to the lab and asked to listen to recordings of four learners – three others and themselves.
Specifically, they were asked to grade the pronunciation of each sentence. In order to ensure that participants would not recognize their own productions, the recordings were manipulated in such a way that the female speakers sounded like male speakers.
“This element of the experimental design is crucial. It was essential that none of listeners would be aware that their own productions were included in the test sample; otherwise their assessments couldn’t be taken as unbiased,” says Holger Mitterer.
The results of this test were unambiguous. In all cases, the listeners rated their own pronunciation as better than others did, even though they were unable to recognize that it was their own recording.
“We were surprised that the experiment so clearly pointed to the significance of overestimation of one’s own abilities in this context,” says Reinisch.
There are several possible explanations for these findings. Previous research has shown that familiar accents are easier to understand than accents that are less familiar.
“One is best acquainted with the sound of one’s own voice, and has no difficulty understanding it,” says Reinisch, who is at LMU’s Institute of Phonetics and Language Processing.
“Perhaps this familiarity leads us to regard our pronunciation as being better than it actually is.” Another possible contributory factor is what is known as the ‘mere exposure’ effect.
This term refers to the fact that we tend to rate things with which we are more familiar – such as the sound of our own voice – as more congenial.
One of the most difficult aspects of learning a foreign language has to do with pronunciation.
The results of the study underline the importance of external feedback in language courses, because it increases the learners; awareness of deficits in language production and comprehension.
“As long as we believe that we are already pretty good, we are not going to put in more effort to improve,” Reinisch points out. A lack of feedback increases the risk of what researchers refer to as ‘fossilization’.
Leaners feel that they have already mastered the unfamiliar articulation patterns in the new language, although that is in fact not the case.
They therefore see no reason why they should invest more time in improving their pronunciation. The authors of the new study are not likely to fall into this sort of error.
They are already considering ways to improve the situation with the aid of apps that generate the necessary external feedback – irrespective of how users rate their own performance.
Adult language learners vary greatly in the quality and speed of acquiring the sound system of a second language (i.e., all segmental and prosodic manifestations on both the phonetic and phonological level). There are numerous possible causes for these differences. The “classic” studies of Foreign Accent have focused on external circumstances of learning such as age of learning, age of arrival, length of residence or amount of L1 and L2 use, but of course other aspects that address learners’ individual characteristics and abilities (e.g., intelligence, personality factors such as extraversion or empathy, attitude or motivation) are also well-researched. The clearest manifestation of such individual learner characteristics is of course the assumption of language or rather pronunciation learning abilities inherent to the speaker, i.e., phonetic talent or aptitude. The successful acquisition of an L2 pronunciation requires, on the one hand, the ability to correctly perceive the phonetic characteristics of that L2, and, on the other hand, the ability to faithfully reproduce these characteristics in her or his own speech. The described perception-production loop is also what characterizes the phenomenon of phonetic convergence, or phonetic adaptation, within a conversational situation—where two talkers become more alike in their pronunciation in the course of a dialog (Pardo, 2006). It may thus be the case that speakers being especially good at converging to their speaking partner during a conversation, also become very good at acquiring the pronunciation of a new dialect or language. Or, in other terms, speakers already displaying a near-native accent in a second language, might be very good phonetic convergers, when observed, for instance in a native-nonnative dialog situation.
Phonetic Convergence
Phonetic convergence describes a process in which the pronunciation of directly interacting partners becomes more similar to each other.
Acoustic measurements have shown speakers to converge on a range of global prosodic and finer-grained segmental features, including utterance duration (Matarazzo et al., 1963; Cappella and Planalp, 1981), response latencies (Street, 1984), pause duration, speech amplitude and turn-taking (Natale, 1975a,b), articulation rate (Schweitzer and Lewandowski, 2013), long-term average spectra (LTAS; Gregory, 1983, 1986; Gregory and Webster, 1996), voice onset time (VOT) and the amount of voicing in vowels (Nielsen, 2011), vowel formant values (Delvaux and Soquet, 2007; Babel, 2012; Schweitzer and Lewandowski, 2014), vowel duration and MFCCs (Delvaux and Soquet, 2007) as well as more global measurements of spectral properties, as amplitude envelope signals (Lewandowski, 2012).
The first wave of studies on speaker adaptation in the 1970s arose from Speech Accommodation Theory (later on Communication Accommodation Theory, e.g., Giles and Powesland, 1975; Simard et al., 1976; Giles, 2001), where accommodation toward a speaking partner was seen as a way to create a socially comforting environment, i.e., boosting social attractiveness and reducing social distance (Giles, 2001).
CAT distinguishes between positive accommodation (convergence) as a means of reducing social distance, divergence—a means increasing social distance, and maintenance—keeping one’s own style (Giles and Ogay, 2006).
Convergence also expresses the need for social approval, group membership and can enhance communicative effectiveness (e.g., by agreeing on joint vocabulary; Pitts and Giles, 2008).
Although the tenets of CAT might imply a certain amount of control over the process, it has not yet been established how far this control extends and which types of linguistic changes might be more prone to the influence of social and psychological factors than others (Lewandowski, 2012).
Pickering and Garrod (e.g., 2004, p. 2, 2004, p. 20, 2005, 2006, 2013) see alignment as largely automatic and very straightforward, whereas other influences (i.e., social or personality-related) are not discussed.
Their mechanistic model proposes that comprehension and production—or in later extensions also listener and speaker expectations and predictions (forward model; Pickering and Garrod, 2013)—become coupled or synchronized during a conversation, therefore a.o. facilitating mutual comprehension (Pickering and Garrod, 2004).
This account is in line with studies on (social) coordination dynamics which also foresees biological hard-wiring of general coordinating behavior in humans (e.g., Kelso, 1997; Kelso and Engstrøm, 2006).
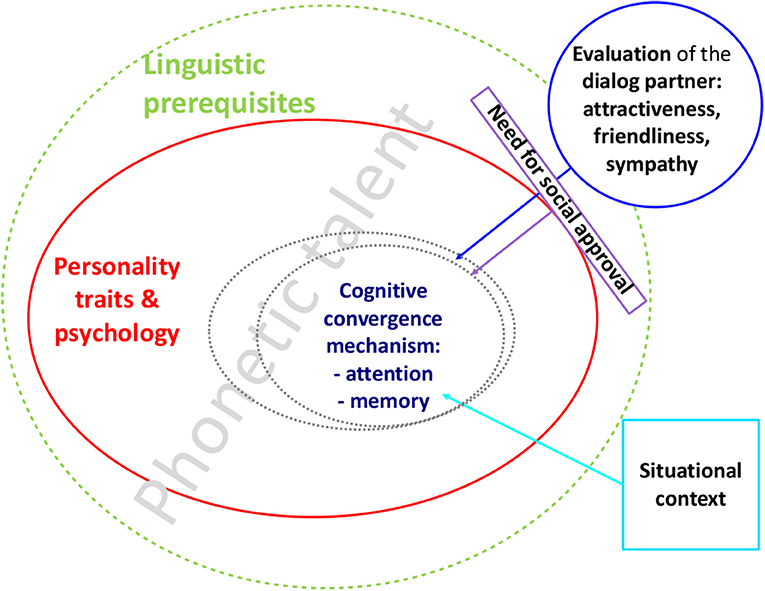
Yet another strand of research into convergence—the hybrid accounts—do not deny a biological core mechanism but concurrently allow for social and psychological influences (e.g., Krauss and Pardo, 2004; Lewandowski, 2012; see also Figure 1).
The elicitation techniques, or scenarios, in which accommodation processes were measured, also varied over the last 50 years.
As accommodation in the CAT terminology involved the presence of a social situation, the effects of adaptation in the early studies were also investigated almost exclusively within conversational interactions: within free or semi-free conversations (Cappella and Planalp, 1981; Gregory, 1983, 1986), with a hidden experimenter (Natale, 1975a), and interviews, in either a laboratory (e.g. Natale, 1975a,b; Street, 1984; Willemyns et al., 1997) or a quasi-natural setting, as e.g., Larry King’s talk show guests (Gregory and Webster, 1996).
In more recent times though, a considerable amount of studies on phonetic speaker adaptation was, for instance, based on shadowing paradigms (see Pardo et al., 2017 for a recent review of non-interactional designs).
These experimental set-ups involve the repetition of words or longer stretches of speech (Namy et al., 2002; Delvaux and Soquet, 2007; Nielsen, 2007, 2008; Babel, 2009; Brouwer et al., 2010; Abrego-Collier et al., 2011), which are either based on modified versions of Goldinger’s shadowing paradigm (Goldinger, 1998), or, for instance, on short question-answer sequences [word games, as e.g., the dominoes game in Bailly and Lelong (2010)].
Another type of set-ups renders dialogs of a still limited linguistic nature (both in terms of utterance length and complexity) and works with assigned talker roles: Map Tasks (Pardo, 2006; Smith, 2007; Pardo et al., 2012, 2013, 2018; Aguilar et al., 2016) and interactive search tasks and games (Dias and Rosenblum, 2011; Levitan et al., 2015).
The last group of studies relies on quasi-spontaneous1 or fully spontaneous conversational data (De Looze et al., 2011; Kim et al., 2011; Schweitzer and Lewandowski, 2013, 2014; Schweitzer et al., 2015).
Pardo et al. (2018) provide an argument for indeed turning toward more natural data for research on pronunciation accommodation by concluding that imitation effects for shadowing2 vs. convergence effects in more interactive forms of communication (MapTasks in this case) might in fact not be directly comparable.
Phonetic convergence arising in fully natural contexts—in interactive, dynamically evolving dialogs—could thus be even further away from the effects we find in imitation studies, e.g., in shadowing.
Taking into account the greatly distinct demands these two scenarios pose for a listener-speakers’ attentional system, which is crucial for the storage and retrieval of appropriate exemplars (be it words, sounds or phrases; see section Individual Cognitive Differences in an Exemplar-Theoretic Account of Language), we would similarly like to encourage a differentiation between the terms imitation, as the measurable adaptation arising in highly linguistically controlled and scripted environments, with limited speech material at hand, and phonetic convergence arising in natural interactions, while juggling the complexity of meaningful conversation with a dialog partner.
We assume that an excellent performance in a shadowing experiment does not automatically indicate or predict an equally high degree of phonetic convergence in running unscripted speech, where attentional resources are necessarily divided upon considerably more parallel tasks, are largely directed at (or away from) pronunciation features naturally (i.e., implicitly), and a number of additional social and contextual factors might enter the equation (see also Lewandowski and Duran, 2018).
Throughout this paper, convergence will thus be referred to meaning spontaneous, naturally emerging adaptation in complex conversational interaction.
Factors Influencing Phonetic Convergence
A considerable amount of factors has been studied in conjunction with phonetic adaptation, predominantly those of an interactive nature, i.e., where the dialog partner or the social context move into the foreground (see schematic model in Figure 1).
Amongst such well-investigated social factors resulting in higher or lower degrees of convergence, are for instance dialog partner evaluations (e.g., friendliness, attractiveness; Pardo et al., 2012; Schweitzer and Lewandowski, 2013, 2014) or social preferences (e.g., racial or sexual bias; Babel, 2009, 2012; Abrego-Collier et al., 2011).
In stark contrast to this lies the almost non-existent body of literature dealing with psychological and personality characteristics of the speaker, or his or her cognitive individual differences and their role in convergence, although they form an essential part of a full model of phonetic convergence.
Lewandowski (2012) proposed a model of phonetic convergence including not only social and contextual factors but also linguistic skills, psychological features and a cognitive core mechanism, which might be related to attention and working memory (WM) skills (see Figure 1).
So far only one study (Yu et al., 2013) reports a correlation between the amount of imitation and the personality feature “openness,” and a further correlation to a test variable from the Autism Spectrum Quotient (AQ, Baron-Cohen et al., 2001) which can be related to attention-switching.
Yu and colleagues’ study, however, does not look into conversational interaction but is an exposure study.
The measure associated with attention-switching is based on a subjective self-questionnaire and not an objective and test-based metric.
Yet no study in phonetic convergence in conversational interaction to date has been devoted to the psychological and cognitive individual differences (IDs) of the speaking partners, which is the main focus of this paper.
Individual Cognitive Differences and Phonological/Phonetic Processing
Although not directly within speaker adaptation studies, the impact of varying attention skills has been investigated in a number of studies on speech perception and production, encompassing clinical and normal populations, and L1 as well as L2 speakers and in plurilingual contexts.
The relationship between bilingualism and attention, for instance, has been put forward in Green’s model of Inhibitory Control (Green, 1998) where bilinguals are said to be permanently faced with the need to inhibit the currently not used language to be able to communicate in the other—a strategy subject to individual differences (Gollan et al., 2011; Lev-Ari and Peperkamp, 2013).
Green’s model also foresees asymmetric switch costs, an effect which can be modulated by the individual’s better inhibition skill, too: speakers with higher inhibitory control scores obtain lower switch costs when shifting between languages (Linck et al., 2012).
Looked at from another perspective, bilingual speakers do seem to profit from a cognitive processing benefit, evident from generally lower switch costs in a Simon Test and faster RTs in tasks with high working memory demands (Bialystok et al., 2004).
The impact of differing attention skills in L2 and bilingual contexts was also studied for VOT productions (Lev-Ari and Peperkamp, 2013), the perception and production of vowels and consonants (Darcy et al., 2016; Safronova, 2016), and tone perception and production (Ou et al., 2015; Ou and Law, 2017).
The effects of poorer attention (switching or inhibitory) control bearing on speech processing have been also previously documented in elderly listeners, leading to stronger perceptual learning effects Scharenborg et al., 2015).
Speech development studies have furthermore found evidence for the essential role attention plays in the fine tuning of perceptual representations (Jusczyk, 2002; Conboy et al., 2008). Analyses of attentional influences in clinical populations, as in Specific Language Impairment (SLI) or developmental dyslexia, brought forward the Sluggish Attentional Shifting Hypothesis (Hari and Renvall, 2001; Lallier et al., 2010) which suggests that dyslectic patients suffer from a prolonged cognitive integration window that induces difficulties in decoding the correct temporal sequence of (speech) units and leads to disturbed rapid stimulus sequence processing (RSS).
Individual Cognitive Differences in an Exemplar-Theoretic Account of Language
Individual differences in cognition and personality leading to differential linguistic performance, including phonetic convergence, can be very straightforwardly modeled in an exemplar-theoretic account—falling within usage-based accounts of language.
Exemplar Theory incorporates recency effects, which are so crucial within speaker adaptation, and can easily aid to explain the straightforward link between perceiving and reproducing someone else’s utterance within a dialog (Goldinger, 1996, 1998; Johnson, 1997; Hawkins, 2003; Pierrehumbert, 2006).
The stored exemplars of speech include rich indexing with, amongst others, labels for speaker identity, language, dialect, accent or situation. Within such a framework the dialog partner has access to an immense pool of exemplars to choose from—in order to adapt to their partner (by finding a closely matching exemplar) or not to adapt (by not finding or not choosing a closely matching exemplar).
Furthermore, it is already at the acquisition stage of an exemplar, where many intermediate steps come into play, introducing much room for IDs between listeners and their prospective phonetic adaptation behavior (Pierrehumbert, 2006).
Lastly, the adaptation process happening between two dialog partners form the microscale, or, the starting point of any further-reaching macroscale processes, as language change – which have been already modeled in usage-based accounts (e.g., Bybee, 2002, 2006).
Within such a usage-based account of language, Pierrehumbert (2006) draws our attention to a suitable solution for the “perfect imitation” problem (i.e., no two instances of the same utterance, word or sound are ever pronounced identically).
Her proposal further divides the acquisition stage of exemplars into intermediate steps of noticing, recognition and coding, forming the basis for the multiple mechanisms standing in between the mere physical experience of a stimulus and its subsequent re-usage in production (Pierrehumbert, 2006). The incoming exemplars are first subject to the operation of noticing.
It is the first and crucial processing step on which all subsequent steps rely. So it seems we have identified an especially powerful cognitive mechanism when it comes to explaining possible IDs in exemplar processing and phonetic convergence—namely attention.
Hawkins (2003) argues that every person (listener, speaker) develops a distinct mental representation of language, simply because categories are self-organizing and emergent.
It follows that every individual is faced with a varying linguistic (and also phonetic) input, and not every person seems to have equal control over the attentional and working memory mechanisms (Robinson, 2003; Cowan et al., 2005; Styles, 2006) which does inevitably surface in processing difficulties of fine acoustic detail necessary for acquiring a native-like pronunciation. Vais et al. (2015), for instance, found a link between speaker talent and accurate use of frequency information in the L2 in their variability study.
This implies that talented L2 learners are better able to build categories from exemplars in the L2. Considering the output—or—retrieval stage of exemplars, Skehan (2003) emphasizes a further advantage of an exemplar-based route over a purely rule-based access system in natural conversations: although the exemplar route might be less flexible and rely on chunks and redundant storage, it is fast and provides convenient access, forming, in his opinion, the basis for both native-like selection and fluency (Skehan, 2003).
Summarizing the links between exemplar-theoretic models and convergence mechanisms, we propose that speakers might be differently endowed with certain cognitive skills (e.g., attention) enhancing or hampering the correct noticing of richly indexed exemplars, as well as their subsequent storage and retrieval in running conversation, leading (amongst other crucial factors, as the aforementioned psychological features) to differences in their degree of phonetic convergence.
Lewandowski (2012) proposes that insufficient attention on fine phonetic detail and the focus shifted toward meaning recognition could interfere with the proper recognition and storage of new acoustic-phonetic exemplars, leading to incomplete or poorly indexed exemplars.
As a consequence, no (sufficient) top-down modulation3 would be possible to help in identifying the currently best items (exemplars) for production at the output stage, since the acoustic-phonetic information (on speaker, accent, dialect etc.) would simply not be stored. This suggests another possible difference in the processing of acoustic-phonetic information by talented and less talented language users.
The Role of Phonetic Talent
The special status of phonetics in L2 acquisition has led to the assumption of a distinct talent component responsible for a person’s success in the L2 phonetics. The same talent factor might also be involved in the mechanism controlling phonetic convergence in a speaker.
Within this concept of language talent L2 research widely accepts the special status of phonetic talent as opposed to other linguistic abilities. Typically a fundamental distinction is drawn between two main substrates of linguistic ability: talent for grammar vs. talent for accent (Schneiderman and Desmarais, 1988).
The additional difficulty of pronunciation acquisition in contrast to other linguistic features is well-known as the so-called “Joseph Conrad Phenomenon” (e.g., Guiora, 1990; Bongaerts et al., 1995; Abu-Rabia and Kehat, 2004), which refers to the Polish-born novelist’s native-like abilities in English grammar (syntax, morphology) and vocabulary apparently having being accompanied by a strongly accented pronunciation.
This separation of pronunciation from other L2 skills has been confirmed in a number of experimental studies. Neufeld (1987), for example, showed that ratings of pronunciation skills did not correlate with the results of general language aptitude tests.
The phonetic subsystem is generally thought to be more difficult to acquire, as it is assumed to rely more on hard-wired biological processes that cannot easily be influenced by conscious learning efforts. Also, in the acquisition of L2 pronunciation there is the additional challenge of having to bypass already established sensory and motor pathways in order to either correctly perceive speech sounds or control articulatory movements.
It is also generally agreed that a distinction has to be drawn between proficiency, i.e., the overtly observable performance of a particular skill, and innate talent or aptitude. Given the same learning circumstances and similar language experience backgrounds, some learners will inevitably be better than others.
Talent or aptitude is thus defined as a stable, innate characteristic that is separate from external circumstances of learning such as experience, input, age of learning etc. as well as other attitudinal factors and personal abilities such as motivation or intelligence. While it is not an indispensable prerequisite for SLA, it does crucially enhance rate and ease of learning (Carroll, 1981).
According to Dörnyei (2005) talent manifests itself via an ideal (or at least very effective) processing of learning conditions and novel information in terms of higher-order cognitive processes (like analysis and inference), lower-order cognitive processes (like pattern recognition) and specifically phonetic abilities like hearing, perception, articulatory flexibility and memory of sound features.
As stated earlier, there is, however, no comprehensive model explaining phonological talent, as it is unclear how phonological skills interact and develop over time (Moyer, 1999).
Proficiency, on the other hand, can be ascertained more directly as the sum of both inherent (such as, for example, talent), and external influence factors (e.g., amount of L1 and L2 use) in an overall performance test (which of course would not reveal the interactions between all these factors).
In order to control for the effect of experience-related factors, it would appear to be the best possible course of action to assemble a large group of test subjects that is homogenous at least with respect to age and “learning career”, i.e., identical time and circumstances of the acquisition of the L2 and then collect as much detailed information as possible on these and all other potentially influential factors such that any correspondences with performance would not remain undetected.
This would also include tests for cognitive (e.g., working memory, intelligence etc.) and socio-psychological (e.g., personality traits) parameters (see the following section on assessment for details), and a measure for motivation.
There are, of course, also tests that are designed to measure general language ability directly or rather predict success at learning a second language, mainly on the basis of the L1 (as the Modern Language Aptitude Test, short MLAT, Carroll and Sapon, 1959).
With regard to a direct assessment of phonetic talent, on the other hand, such tests or a combination of tests have yet to be established. In fact, one of the objectives the extensive investigation of the neural correlates of pronunciation talent (Dogil and Reiterer, 2009) referred to in later sections had, was to gain a better insight into specific abilities or tasks that would be particularly representative with respect to that purpose.
It is also in this sense that the ability of some speakers to adapt to the phonetic characteristics of other speakers (as defined in Subjects) might be interpreted as an expression of talent, while it (i.e., phonetic convergence) might nevertheless in turn be connected to and/or influenced by yet other individual factors, as well as contextual and social factors (see section Factors Influencing Phonetic Convergence).
Motivation and Goals
As described in the introductory part, the impact of social factors on phonetic adaptation (including but not limited to social and professional status, mutual liking, and aspects of dominance) has so far received considerably more attention within studies on phonetic adaptation than personality features and cognitive factors—including pronunciation talent.
The phonetic adaptation mechanism though, lying at the intersection of perception and production, is in our opinion susceptible not only to social and contextual influences (external factors) but also, and maybe foremost, to factors lying within the listeners-speakers themselves (internal factors).
Analyzing the convergence mechanism from an exemplar-theoretic angle, all steps of the perception-production loop (noticing, recognition, (en)coding, retrieval and production) pose great demands on the language user’s cognitive functions, which differ largely from one person to another.
We assume that individual differences in executive attention, and possibly also working memory components, have a considerable impact on the degree of convergence. The skillful and fast directing of attention toward the relevant acoustic-phonetic features is crucial for success in both storage and retrieval of exemplars.
Such a competent employment of attentional resources could allow for the storage of richer-indexed exemplars, retaining more relevant acoustic-phonetic features, which can later on be accessed for production (on top of facilitating the retrieval process itself).
Precisely this skill—a better employment of executive attention—might also be the one setting apart the phonetically talented speakers in our study from the phonetically less talented ones, leading to potentially more phonetic convergence in the former group.
A person striving for (be it consciously or subconsciously) for convergence, must first possess the necessary skill to do so—a certain aptitude for fast storage and re-usage of acoustic-phonetic material.
Observed the other way round: a good converger, adapting to their speaking partner’s pronunciation in an L2, has a high chance of being a talented and successful acquirer of this L2’s proper pronunciation in general.
In addition to that, we assume that some personality features can further facilitate this convergence process, by potentially mediating the top-down directed attention at the partner’s language, and more specifically at her or his pronunciation.
This, again, influences the amount of adaptation possible—or desired. We would, for example, expect personality features as openness (see also Yu et al., 2013) and extraversion to positively impact the degree of convergence, and measures as the Behavior Inhibition Scale (BIS) to stand in a negative relationship to the amount of convergence.
In what follows, we will first describe the procedures of the background study (also referred to as the language talent study from this point onwards) on Language Talent and the Brain (see Dogil and Reiterer, 2009).
Our current study on phonetic convergence and the language talent study share participants. The subjects for the convergence study have been chosen amongst the large pool of participants of the talent study, guided by their performance therein.
Apart from the linguistic tests allowing for a classification of the speakers into a talented and less talented group, the language talent study also contained a number of additional psychological and cognitive data on the participants, in parts selected for the analysis of convergence in the main study.
The second part will be concerned with the methodology of our main study—the analysis of phonetic convergence in relation to the phonetic talent of our participants, as determined through the linguistic tests in the language talent study (Dogil and Reiterer, 2009; Jilka, 2009a), and to their personality and cognitive skills.
Language Talent Study: Identification and Classification of Pronunciation Talent in Language Learners (Dogil and Reiterer, 2009)
As indicated in the preceding section, the selection of suitable participants for the phonetic convergence study (our main study, described in section Main Study: Testing Phonetic Convergence in a Conversational Setting) was based on an earlier project that had the objective of providing a comprehensive examination of talent in second language pronunciation—the language talent study (Dogil and Reiterer, 2009; see also Jilka et al., 2010).
It investigated this ability with respect to its multiple phonetic/linguistic manifestations, attempting to take into account the large variety of influence factors. The main goal was to facilitate further investigations into finding neural correlates of pronunciation talent, i.e., differences in brain activity between talented and untalented speakers.
Source:
LMU Munich



{kind=link}