










 Extract (6-MSITC) in Healthy Older Adults")
: An In-Depth Exploration into its Thermogenic Role and Social Significance")



A new Dutch study tested whether a simple mental activity – having children with low self-confidence say favorable, encouraging words to themselves – could boost their achievement.
The study found that children who engaged in this kind of self-talk improved their math performance when the talk focused on effort, not ability.
The study was done by researchers at Utrecht University, the University of Applied Sciences Leiden, the University of Amsterdam, and the University of Southampton.
It appears in Child Development, a journal of the Society for Research in Child Development.
“Parents and teachers are often advised to encourage children to repeat positive self-statements at stressful times, such as when they’re taking academic tests,” notes Sander Thomaes, professor of psychology at Utrecht University, who led the study.
“But until now, we didn’t have a good idea of whether this helped children’s achievement. We discovered that children with low self-confidence can improve their performance through self-talk focused on effort, a self-regulation strategy that children can do by themselves every day.”
Researchers examined 212 children in grades 4 to 6 (ages 9 to 13 years) from schools in middle-class communities in the Netherlands.
They chose this age because in late childhood, negative perceptions of competence on school tasks become increasingly prevalent.
The children were instructed to take a math test because math performance is compromised by negative beliefs about one’s competence.
In the study, the children first reported their beliefs about their competence. A few days later, they worked in their classrooms on the first half of a standardized math test.
Immediately after completing the first half of the test, they were randomly assigned to silently take part in either self-talk focused on effort (e.g., “I will do my very best!”), self-talk focused on ability (“I am very good at this!”), or no self-talk.
Afterwards, they completed the second half of the math test.
Children who took part in self-talk focused on effort improved their performance on the test compared to children who did not engage in self-talk focused on effort.
The benefits of self-talk were especially pronounced among children who held negative beliefs about their competence. In contrast, children who engaged in self-talk focused on ability did not improve their math scores, regardless of their beliefs about their competence.
“Our study found that the math performance of children with low self-confidence benefits when they tell themselves that they will make an effort,” explains Eddie Brummelman, assistant professor of child development at the University of Amsterdam, who coauthored the study. “We did not find the same result among children with low self-confidence who spoke to themselves about ability. Self-talk about effort is the key.”
The authors note that their findings apply only to children in fourth to sixth grades and may not be applicable to children of other ages.
They also note that the study was done in the Netherlands, and that children’s response to self-talk may differ in other countries and cultures.
Defining and Operationalizing Student Self-Assessment
Without exception, reviews of self-assessment (Sargeant, 2008; Brown and Harris, 2013; Panadero et al., 2016a) call for clearer definitions: What is self-assessment, and what is not?
This question is surprisingly difficult to answer, as the term self-assessment has been used to describe a diverse range of activities, such as assigning a happy or sad face to a story just told, estimating the number of correct answers on a math test, graphing scores for dart throwing, indicating understanding (or the lack thereof) of a science concept, using a rubric to identify strengths and weaknesses in one’s persuasive essay, writing reflective journal entries, and so on.
Each of those activities involves some kind of assessment of one’s own functioning, but they are so different that distinctions among types of self-assessment are needed. I will draw those distinctions in terms of the purposes of self-assessment which, in turn, determine its features: a classic form-fits-function analysis.
What is Self-Assessment?
Brown and Harris (2013) defined self-assessment in the K-16 context as a “descriptive and evaluative act carried out by the student concerning his or her own work and academic abilities” (p. 368). Panadero et al. (2016a) defined it as a “wide variety of mechanisms and techniques through which students describe (i.e., assess) and possibly assign merit or worth to (i.e., evaluate) the qualities of their own learning processes and products” (p. 804). Referring to physicians, Epstein et al. (2008) defined “concurrent self-assessment” as “ongoing moment-to-moment self-monitoring” (p. 5).
Self-monitoring “refers to the ability to notice our own actions, curiosity to examine the effects of those actions, and willingness to use those observations to improve behavior and thinking in the future” (p. 5). Taken together, these definitions include self-assessment of one’s abilities, processes, and products—everything but the kitchen sink.
This very broad conception might seem unwieldy, but it works because each object of assessment—competence, process, and product—is subject to the influence of feedback from oneself.
What is missing from each of these definitions, however, is the purpose of the act of self-assessment. Their authors might rightly point out that the purpose is implied, but a formal definition requires us to make it plain: Why do we ask students to self-assess?
I have long held that self-assessment is feedback (Andrade, 2010), and that the purpose of feedback is to inform adjustments to processes and products that deepen learning and enhance performance; hence the purpose of self-assessment is to generate feedback that promotes learning and improvements in performance.
This learning-oriented purpose of self-assessment implies that it should be formative: if there is no opportunity for adjustment and correction, self-assessment is almost pointless.
Why Self-Assess?
Clarity about the purpose of self-assessment allows us to interpret what otherwise appear to be discordant findings from research, which has produced mixed results in terms of both the accuracy of students’ self-assessments and their influence on learning and/or performance. I believe the source of the discord can be traced to the different ways in which self-assessment is carried out, such as whether it is summative and formative.
This issue will be taken up again in the review of current research that follows this overview. For now, consider a study of the accuracy and validity of summative self-assessment in teacher education conducted by Tejeiro et al. (2012), which showed that students’ self-assigned marks tended to be higher than marks given by professors.
All 122 students in the study assigned themselves a grade at the end of their course, but half of the students were told that their self-assigned grade would count toward 5% of their final grade. In both groups, students’ self-assessments were higher than grades given by professors, especially for students with “poorer results” (p. 791) and those for whom self-assessment counted toward the final grade.
In the group that was told their self-assessments would count toward their final grade, no relationship was found between the professor’s and the students’ assessments. Tejeiro et al. concluded that, although students’ and professor’s assessments tend to be highly similar when self-assessment did not count toward final grades, overestimations increased dramatically when students’ self-assessments did count. Interviews of students who self-assigned highly discrepant grades revealed (as you might guess) that they were motivated by the desire to obtain the highest possible grades.
Studies like Tejeiro et al’s. (2012) are interesting in terms of the information they provide about the relationship between consistency and honesty, but the purpose of the self-assessment, beyond addressing interesting research questions, is unclear. There is no feedback purpose.
This is also true for another example of a study of summative self-assessment of competence, during which elementary-school children took the Test of Narrative Language and then were asked to self-evaluate “how you did in making up stories today” by pointing to one of five pictures, from a “very happy face” (rating of five) to a “very sad face” (rating of one) (Kaderavek et al., 2004. p. 37)
. The usual results were reported: Older children and good narrators were more accurate than younger children and poor narrators, and males tended to more frequently overestimate their ability.
Typical of clinical studies of accuracy in self-evaluation, this study rests on a definition and operationalization of self-assessment with no value in terms of instructional feedback. If those children were asked to rate their stories and then revise or, better yet, if they assessed their stories according to clear, developmentally appropriate criteria before revising, the valence of their self-assessments in terms of instructional feedback would skyrocket.
I speculate that their accuracy would too. In contrast, studies of formative self-assessment suggest that when the act of self-assessing is given a learning-oriented purpose, students’ self-assessments are relatively consistent with those of external evaluators, including professors (Lopez and Kossack, 2007; Barney et al., 2012; Leach, 2012), teachers (Bol et al., 2012; Chang et al., 2012, 2013), researchers (Panadero and Romero, 2014; Fitzpatrick and Schulz, 2016), and expert medical assessors (Hawkins et al., 2012).
My commitment to keeping self-assessment formative is firm. However, Gavin Brown (personal communication, April 2011) reminded me that summative self-assessment exists and we cannot ignore it; any definition of self-assessment must acknowledge and distinguish between formative and summative forms of it.
Thus, the taxonomy in Table 1, which depicts self-assessment as serving formative and/or summative purposes, and focuses on competence, processes, and/or products.
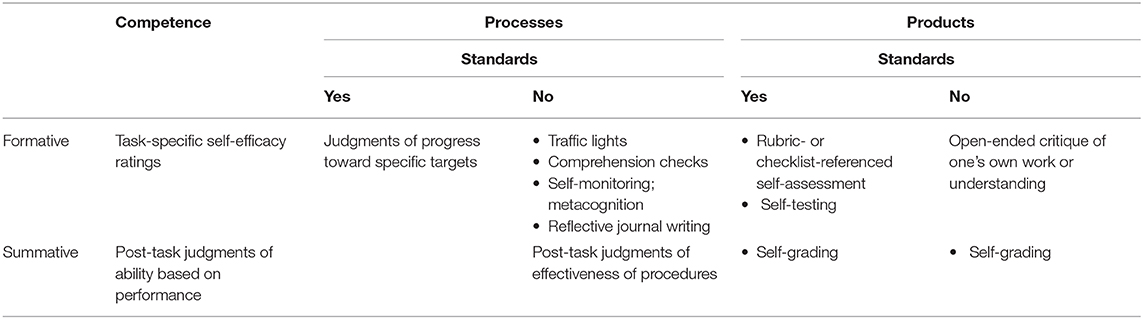
Fortunately, a formative view of self-assessment seems to be taking hold in various educational contexts. For instance, Sargeant (2008) noted that all seven authors in a special issue of the Journal of Continuing Education in the Health Professions “conceptualize self-assessment within a formative, educational perspective, and see it as an activity that draws upon both external and internal data, standards, and resources to inform and make decisions about one’s performance” (p. 1). Sargeant also stresses the point that self-assessment should be guided by evaluative criteria: “Multiple external sources can and should inform self-assessment, perhaps most important among them performance standards” (p. 1). Now we are talking about the how of self-assessment, which demands an operationalization of self-assessment practice. Let us examine each object of self-assessment (competence, processes, and/or products) with an eye for what is assessed and why.
What is Self-Assessed?
Monitoring and self-assessing processes are practically synonymous with self-regulated learning (SRL), or at least central components of it such as goal-setting and monitoring, or metacognition. Research on SRL has clearly shown that self-generated feedback on one’s approach to learning is associated with academic gains (Zimmerman and Schunk, 2011). Self-assessment of the products, such as papers and presentations, are the easiest to defend as feedback, especially when those self-assessments are grounded in explicit, relevant, evaluative criteria and followed by opportunities to relearn and/or revise (Andrade, 2010).
Including the self-assessment of competence in this definition is a little trickier. I hesitated to include it because of the risk of sneaking in global assessments of one’s overall ability, self-esteem, and self-concept (“I’m good enough, I’m smart enough, and doggone it, people like me,” Franken, 1992), which do not seem relevant to a discussion of feedback in the context of learning. Research on global self-assessment, or self-perception, is popular in the medical education literature, but even there, scholars have begun to question its usefulness in terms of influencing learning and professional growth (e.g., see Sargeant et al., 2008). Eva and Regehr (2008) seem to agree in the following passage, which states the case in a way that makes it worthy of a long quotation:
Self-assessment is often (implicitly or otherwise) conceptualized as a personal, unguided reflection on performance for the purposes of generating an individually derived summary of one’s own level of knowledge, skill, and understanding in a particular area. For example, this conceptualization would appear to be the only reasonable basis for studies that fit into what Colliver et al. (2005) has described as the “guess your grade” model of self-assessment research, the results of which form the core foundation for the recurring conclusion that self-assessment is generally poor. This unguided, internally generated construction of self-assessment stands in stark contrast to the model put forward by Boud (1999), who argued that the phrase self-assessment should not imply an isolated or individualistic activity; it should commonly involve peers, teachers, and other sources of information. The conceptualization of self-assessment as enunciated in Boud’s description would appear to involve a process by which one takes personal responsibility for looking outward, explicitly seeking feedback, and information from external sources, then using these externally generated sources of assessment data to direct performance improvements. In this construction, self-assessment is more of a pedagogical strategy than an ability to judge for oneself; it is a habit that one needs to acquire and enact rather than an ability that one needs to master (p. 15).
As in the K-16 context, self-assessment is coming to be seen as having value as much or more so in terms of pedagogy as in assessment (Silver et al., 2008; Brown and Harris, 2014). In the end, however, I decided that self-assessing one’s competence to successfully learn a particular concept or complete a particular task (which sounds a lot like self-efficacy—more on that later) might be useful feedback because it can inform decisions about how to proceed, such as the amount of time to invest in learning how to play the flute, or whether or not to seek help learning the steps of the jitterbug. An important caveat, however, is that self-assessments of competence are only useful if students have opportunities to do something about their perceived low competence—that is, it serves the purpose of formative feedback for the learner.
How to Self-Assess?
Panadero et al. (2016a) summarized five very different taxonomies of self-assessment and called for the development of a comprehensive typology that considers, among other things, its purpose, the presence or absence of criteria, and the method. In response, I propose the taxonomy depicted in Table 1, which focuses on the what (competence, process, or product), the why (formative or summative), and the how (methods, including whether or not they include standards, e.g., criteria) of self-assessment. The collections of examples of methods in the table is inexhaustive.
I put the methods in Table 1 where I think they belong, but many of them could be placed in more than one cell. Take self-efficacy, for instance, which is essentially a self-assessment of one’s competence to successfully undertake a particular task (Bandura, 1997). Summative judgments of self-efficacy are certainly possible but they seem like a silly thing to do—what is the point, from a learning perspective? Formative self-efficacy judgments, on the other hand, can inform next steps in learning and skill building. There is reason to believe that monitoring and making adjustments to one’s self-efficacy (e.g., by setting goals or attributing success to effort) can be productive (Zimmerman, 2000), so I placed self-efficacy in the formative row.
It is important to emphasize that self-efficacy is task-specific, more or less (Bandura, 1997). This taxonomy does not include general, holistic evaluations of one’s abilities, for example, “I am good at math.” Global assessment of competence does not provide the leverage, in terms of feedback, that is provided by task-specific assessments of competence, that is, self-efficacy. Eva and Regehr (2008) provided an illustrative example: “We suspect most people are prompted to open a dictionary as a result of encountering a word for which they are uncertain of the meaning rather than out of a broader assessment that their vocabulary could be improved” (p. 16). The exclusion of global evaluations of oneself resonates with research that clearly shows that feedback that focuses on aspects of a task (e.g., “I did not solve most of the algebra problems”) is more effective than feedback that focuses on the self (e.g., “I am bad at math”) (Kluger and DeNisi, 1996; Dweck, 2006; Hattie and Timperley, 2007). Hence, global self-evaluations of ability or competence do not appear in Table 1.
Another approach to student self-assessment that could be placed in more than one cell is traffic lights. The term traffic lights refers to asking students to use green, yellow, or red objects (or thumbs up, sideways, or down—anything will do) to indicate whether they think they have good, partial, or little understanding (Black et al., 2003). It would be appropriate for traffic lights to appear in multiple places in Table 1, depending on how they are used. Traffic lights seem to be most effective at supporting students’ reflections on how well they understand a concept or have mastered a skill, which is line with their creators’ original intent, so they are categorized as formative self-assessments of one’s learning—which sounds like metacognition.
In fact, several of the methods included in Table 1 come from research on metacognition, including self-monitoring, such as checking one’s reading comprehension, and self-testing, e.g., checking one’s performance on test items. These last two methods have been excluded from some taxonomies of self-assessment (e.g., Boud and Brew, 1995) because they do not engage students in explicitly considering relevant standards or criteria. However, new conceptions of self-assessment are grounded in theories of the self- and co-regulation of learning (Andrade and Brookhart, 2016), which includes self-monitoring of learning processes with and without explicit standards.
However, my research favors self-assessment with regard to standards (Andrade and Boulay, 2003; Andrade and Du, 2007; Andrade et al., 2008, 2009, 2010), as does related research by Panadero and his colleagues (see below). I have involved students in self-assessment of stories, essays, or mathematical word problems according to rubrics or checklists with criteria. For example, two studies investigated the relationship between elementary or middle school students’ scores on a written assignment and a process that involved them in reading a model paper, co-creating criteria, self-assessing first drafts with a rubric, and revising (Andrade et al., 2008, 2010). The self-assessment was highly scaffolded: students were asked to underline key phrases in the rubric with colored pencils (e.g., underline “clearly states an opinion” in blue), then underline or circle in their drafts the evidence of having met the standard articulated by the phrase (e.g., his or her opinion) with the same blue pencil. If students found they had not met the standard, they were asked to write themselves a reminder to make improvements when they wrote their final drafts. This process was followed for each criterion on the rubric. There were main effects on scores for every self-assessed criterion on the rubric, suggesting that guided self-assessment according to the co-created criteria helped students produce more effective writing.
Panadero and his colleagues have also done quasi-experimental and experimental research on standards-referenced self-assessment, using rubrics or lists of assessment criteria that are presented in the form of questions (Panadero et al., 2012, 2013, 2014; Panadero and Romero, 2014). Panadero calls the list of assessment criteria a script because his work is grounded in research on scaffolding (e.g., Kollar et al., 2006): I call it a checklist because that is the term used in classroom assessment contexts. Either way, the list provides standards for the task. Here is a script for a written summary that Panadero et al. (2014) used with college students in a psychology class:
• Does my summary transmit the main idea from the text? Is it at the beginning of my summary?
• Are the important ideas also in my summary?
• Have I selected the main ideas from the text to make them explicit in my summary?
• Have I thought about my purpose for the summary? What is my goal?
Taken together, the results of the studies cited above suggest that students who engaged in self-assessment using scripts or rubrics were more self-regulated, as measured by self-report questionnaires and/or think aloud protocols, than were students in the comparison or control groups. Effect sizes were very small to moderate (η2 = 0.06–0.42), and statistically significant. Most interesting, perhaps, is one study (Panadero and Romero, 2014) that demonstrated an association between rubric-referenced self-assessment activities and all three phases of SRL; forethought, performance, and reflection.
There are surely many other methods of self-assessment to include in Table 1, as well as interesting conversations to be had about which method goes where and why. In the meantime, I offer the taxonomy in Table 1 as a way to define and operationalize self-assessment in instructional contexts and as a framework for the following overview of current research on the subject.
An Overview of Current Research on Self-Assessment
Several recent reviews of self-assessment are available (Brown and Harris, 2013; Brown et al., 2015; Panadero et al., 2017), so I will not summarize the entire body of research here. Instead, I chose to take a birds-eye view of the field, with goal of reporting on what has been sufficiently researched and what remains to be done. I used the references lists from reviews, as well as other relevant sources, as a starting point. In order to update the list of sources, I directed two new searches1, the first of the ERIC database, and the second of both ERIC and PsychINFO. Both searches included two search terms, “self-assessment” OR “self-evaluation.” Advanced search options had four delimiters: (1) peer-reviewed, (2) January, 2013–October, 2016 and then October 2016–March 2019, (3) English, and (4) full-text. Because the focus was on K-20 educational contexts, sources were excluded if they were about early childhood education or professional development.
The first search yielded 347 hits; the second 1,163. Research that was unrelated to instructional feedback was excluded, such as studies limited to self-estimates of performance before or after taking a test, guesses about whether a test item was answered correctly, and estimates of how many tasks could be completed in a certain amount of time. Although some of the excluded studies might be thought of as useful investigations of self-monitoring, as a group they seemed too unrelated to theories of self-generated feedback to be appropriate for this review. Seventy-six studies were selected for inclusion in Table S1 (Supplementary Material), which also contains a few studies published before 2013 that were not included in key reviews, as well as studies solicited directly from authors.
The Table S1 in the Supplementary Material contains a complete list of studies included in this review, organized by the focus or topic of the study, as well as brief descriptions of each. The “type” column Table S1 (Supplementary Material) indicates whether the study focused on formative or summative self-assessment. This distinction was often difficult to make due to a lack of information. For example, Memis and Seven (2015) frame their study in terms of formative assessment, and note that the purpose of the self-evaluation done by the sixth grade students is to “help students improve their [science] reports” (p. 39), but they do not indicate how the self-assessments were done, nor whether students were given time to revise their reports based on their judgments or supported in making revisions. A sentence or two of explanation about the process of self-assessment in the procedures sections of published studies would be most useful.
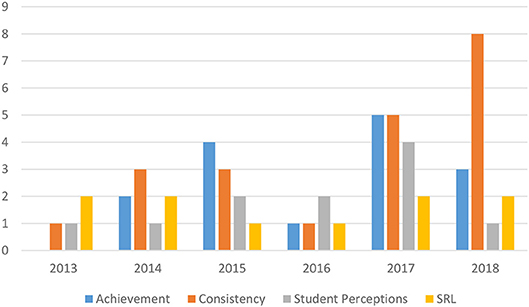
Figure 1 graphically represents the number of studies in the four most common topic categories found in the table—achievement, consistency, student perceptions, and SRL. The figure reveals that research on self-assessment is on the rise, with consistency the most popular topic. Of the 76 studies in the table in the appendix, 44 were inquiries into the consistency of students’ self-assessments with other judgments (e.g., a test score or teacher’s grade). Twenty-five studies investigated the relationship between self-assessment and achievement. Fifteen explored students’ perceptions of self-assessment. Twelve studies focused on the association between self-assessment and self-regulated learning. One examined self-efficacy, and two qualitative studies documented the mental processes involved in self-assessment. The sum (n = 99) of the list of research topics is more than 76 because several studies had multiple foci. In the remainder of this review I examine each topic in turn.
Consistency
Table S1 (Supplementary Material) reveals that much of the recent research on self-assessment has investigated the accuracy or, more accurately, consistency, of students’ self-assessments. The term consistency is more appropriate in the classroom context because the quality of students’ self-assessments is often determined by comparing them with their teachers’ assessments and then generating correlations. Given the evidence of the unreliability of teachers’ grades (Falchikov, 2005), the assumption that teachers’ assessments are accurate might not be well-founded (Leach, 2012; Brown et al., 2015). Ratings of student work done by researchers are also suspect, unless evidence of the validity and reliability of the inferences made about student work by researchers is available. Consequently, much of the research on classroom-based self-assessment should use the term consistency, which refers to the degree of alignment between students’ and expert raters’ evaluations, avoiding the purer, more rigorous term accuracy unless it is fitting.
In their review, Brown and Harris (2013) reported that correlations between student self-ratings and other measures tended to be weakly to strongly positive, ranging from r ≈ 0.20 to 0.80, with few studies reporting correlations >0.60. But their review included results from studies of any self-appraisal of school work, including summative self-rating/grading, predictions about the correctness of answers on test items, and formative, criteria-based self-assessments, a combination of methods that makes the correlations they reported difficult to interpret. Qualitatively different forms of self-assessment, especially summative and formative types, cannot be lumped together without obfuscating important aspects of self-assessment as feedback.
Given my concern about combining studies of summative and formative assessment, you might anticipate a call for research on consistency that distinguishes between the two. I will make no such call for three reasons. One is that we have enough research on the subject, including the 22 studies in Table S1 (Supplementary Material) that were published after Brown and Harris’s review (2013). Drawing only on studies included in Table S1 (Supplementary Material), we can say with confidence that summative self-assessment tends to be inconsistent with external judgements (Baxter and Norman, 2011; De Grez et al., 2012; Admiraal et al., 2015), with males tending to overrate and females to underrate (Nowell and Alston, 2007; Marks et al., 2018). There are exceptions (Alaoutinen, 2012; Lopez-Pastor et al., 2012) as well as mixed results, with students being consistent regarding some aspects of their learning but not others (Blanch-Hartigan, 2011; Harding and Hbaci, 2015; Nguyen and Foster, 2018). We can also say that older, more academically competent learners tend to be more consistent (Hacker et al., 2000; Lew et al., 2010; Alaoutinen, 2012; Guillory and Blankson, 2017; Butler, 2018; Nagel and Lindsey, 2018). There is evidence that consistency can be improved through experience (Lopez and Kossack, 2007; Yilmaz, 2017; Nagel and Lindsey, 2018), the use of guidelines (Bol et al., 2012), feedback (Thawabieh, 2017), and standards (Baars et al., 2014), perhaps in the form of rubrics (Panadero and Romero, 2014). Modeling and feedback also help (Labuhn et al., 2010; Miller and Geraci, 2011; Hawkins et al., 2012; Kostons et al., 2012).
An outcome typical of research on the consistency of summative self-assessment can be found in row 59, which summarizes the study by Tejeiro et al. (2012) discussed earlier: Students’ self-assessments were higher than marks given by professors, especially for students with poorer results, and no relationship was found between the professors’ and the students’ assessments in the group in which self-assessment counted toward the final mark. Students are not stupid: if they know that they can influence their final grade, and that their judgment is summative rather than intended to inform revision and improvement, they will be motivated to inflate their self-evaluation. I do not believe we need more research to demonstrate that phenomenon.
The second reason I am not calling for additional research on consistency is a lot of it seems somewhat irrelevant. This might be because the interest in accuracy is rooted in clinical research on calibration, which has very different aims. Calibration accuracy is the “magnitude of consent between learners’ true and self-evaluated task performance. Accurately calibrated learners’ task performance equals their self-evaluated task performance” (Wollenschläger et al., 2016). Calibration research often asks study participants to predict or postdict the correctness of their responses to test items. I caution about generalizing from clinical experiments to authentic classroom contexts because the dismal picture of our human potential to self-judge was painted by calibration researchers before study participants were effectively taught how to predict with accuracy, or provided with the tools they needed to be accurate, or motivated to do so. Calibration researchers know that, of course, and have conducted intervention studies that attempt to improve accuracy, with some success (e.g., Bol et al., 2012). Studies of formative self-assessment also suggest that consistency increases when it is taught and supported in many of the ways any other skill must be taught and supported (Lopez and Kossack, 2007; Labuhn et al., 2010; Chang et al., 2012, 2013; Hawkins et al., 2012; Panadero and Romero, 2014; Lin-Siegler et al., 2015; Fitzpatrick and Schulz, 2016).
Even clinical psychological studies that go beyond calibration to examine the associations between monitoring accuracy and subsequent study behaviors do not transfer well to classroom assessment research. After repeatedly encountering claims that, for example, low self-assessment accuracy leads to poor task-selection accuracy and “suboptimal learning outcomes” (Raaijmakers et al., 2019, p. 1), I dug into the cited studies and discovered two limitations. The first is that the tasks in which study participants engage are quite inauthentic. A typical task involves studying “word pairs (e.g., railroad—mother), followed by a delayed judgment of learning (JOL) in which the students predicted the chances of remembering the pair… After making a JOL, the entire pair was presented for restudy for 4 s [sic], and after all pairs had been restudied, a criterion test of paired-associate recall occurred” (Dunlosky and Rawson, 2012, p. 272). Although memory for word pairs might be important in some classroom contexts, it is not safe to assume that results from studies like that one can predict students’ behaviors after criterion-referenced self-assessment of their comprehension of complex texts, lengthy compositions, or solutions to multi-step mathematical problems.
The second limitation of studies like the typical one described above is more serious: Participants in research like that are not permitted to regulate their own studying, which is experimentally manipulated by a computer program. This came as a surprise, since many of the claims were about students’ poor study choices but they were rarely allowed to make actual choices. For example, Dunlosky and Rawson (2012) permitted participants to “use monitoring to effectively control learning” by programming the computer so that “a participant would need to have judged his or her recall of a definition entirely correct on three different trials, and once they judged it entirely correct on the third trial, that particular key term definition was dropped [by the computer program] from further practice” (p. 272). The authors note that this study design is an improvement on designs that did not require all participants to use the same regulation algorithm, but it does not reflect the kinds of decisions that learners make in class or while doing homework. In fact, a large body of research shows that students can make wise choices when they self-pace the study of to-be-learned materials and then allocate study time to each item (Bjork et al., 2013, p. 425):
In a typical experiment, the students first study all the items at an experimenter-paced rate (e.g., study 60 paired associates for 3 s each), which familiarizes the students with the items; after this familiarity phase, the students then either choose which items they want to restudy (e.g., all items are presented in an array, and the students select which ones to restudy) and/or pace their restudy of each item. Several dependent measures have been widely used, such as how long each item is studied, whether an item is selected for restudy, and in what order items are selected for restudy. The literature on these aspects of self-regulated study is massive (for a comprehensive overview, see both Dunlosky and Ariel, 2011 and Son and Metcalfe, 2000), but the evidence is largely consistent with a few basic conclusions. First, if students have a chance to practice retrieval prior to restudying items, they almost exclusively choose to restudy unrecalled items and drop the previously recalled items from restudy (Metcalfe and Kornell, 2005). Second, when pacing their study of individual items that have been selected for restudy, students typically spend more time studying items that are more, rather than less, difficult to learn. Such a strategy is consistent with a discrepancy-reduction model of self-paced study (which states that people continue to study an item until they reach mastery), although some key revisions to this model are needed to account for all the data. For instance, students may not continue to study until they reach some static criterion of mastery, but instead, they may continue to study until they perceive that they are no longer making progress.
I propose that this research, which suggests that students’ unscaffolded, unmeasured, informal self-assessments tend to lead to appropriate task selection, is better aligned with research on classroom-based self-assessment. Nonetheless, even this comparison is inadequate because the study participants were not taught to compare their performance to the criteria for mastery, as is often done in classroom-based self-assessment.
The third and final reason I do not believe we need additional research on consistency is that I think it is a distraction from the true purposes of self-assessment. Many if not most of the articles about the accuracy of self-assessment are grounded in the assumption that accuracy is necessary for self-assessment to be useful, particularly in terms of subsequent studying and revision behaviors. Although it seems obvious that accurate evaluations of their performance positively influence students’ study strategy selection, which should produce improvements in achievement, I have not seen relevant research that tests those conjectures. Some claim that inaccurate estimates of learning lead to the selection of inappropriate learning tasks (Kostons et al., 2012) but they cite research that does not support their claim. For example, Kostons et al. cite studies that focus on the effectiveness of SRL interventions but do not address the accuracy of participants’ estimates of learning, nor the relationship of those estimates to the selection of next steps. Other studies produce findings that support my skepticism. Take, for instance, two relevant studies of calibration. One suggested that performance and judgments of performance had little influence on subsequent test preparation behavior (Hacker et al., 2000), and the other showed that study participants followed their predictions of performance to the same degree, regardless of monitoring accuracy (van Loon et al., 2014).
Eva and Regehr (2008) believe that:
Research questions that take the form of “How well do various practitioners self-assess?” “How can we improve self-assessment?” or “How can we measure self-assessment skill?” should be considered defunct and removed from the research agenda [because] there have been hundreds of studies into these questions and the answers are “Poorly,” “You can’t,” and “Don’t bother” (p. 18).
I almost agree. A study that could change my mind about the importance of accuracy of self-assessment would be an investigation that goes beyond attempting to improve accuracy just for the sake of accuracy by instead examining the relearning/revision behaviors of accurate and inaccurate self-assessors: Do students whose self-assessments match the valid and reliable judgments of expert raters (hence my use of the term accuracy) make better decisions about what they need to do to deepen their learning and improve their work? Here, I admit, is a call for research related to consistency: I would love to see a high-quality investigation of the relationship between accuracy in formative self-assessment, and students’ subsequent study and revision behaviors, and their learning. For example, a study that closely examines the revisions to writing made by accurate and inaccurate self-assessors, and the resulting outcomes in terms of the quality of their writing, would be most welcome.
Table S1 (Supplementary Material) indicates that by 2018 researchers began publishing studies that more directly address the hypothesized link between self-assessment and subsequent learning behaviors, as well as important questions about the processes learners engage in while self-assessing (Yan and Brown, 2017). One, a study by Nugteren et al. (2018 row 19 in Table S1 (Supplementary Material)), asked “How do inaccurate [summative] self-assessments influence task selections?” (p. 368) and employed a clever exploratory research design. The results suggested that most of the 15 students in their sample over-estimated their performance and made inaccurate learning-task selections. Nugteren et al. recommended helping students make more accurate self-assessments, but I think the more interesting finding is related to why students made task selections that were too difficult or too easy, given their prior performance: They based most task selections on interest in the content of particular items (not the overarching content to be learned), and infrequently considered task difficulty and support level. For instance, while working on the genetics tasks, students reported selecting tasks because they were fun or interesting, not because they addressed self-identified weaknesses in their understanding of genetics. Nugteren et al. proposed that students would benefit from instruction on task selection. I second that proposal: Rather than directing our efforts on accuracy in the service of improving subsequent task selection, let us simply teach students to use the information at hand to select next best steps, among other things.
Butler (2018, row 76 in Table S1 (Supplementary Material)) has conducted at least two studies of learners’ processes of responding to self-assessment items and how they arrived at their judgments. Comparing generic, decontextualized items to task-specific, contextualized items (which she calls after-task items), she drew two unsurprising conclusions: the task-specific items “generally showed higher correlations with task performance,” and older students “appeared to be more conservative in their judgment compared with their younger counterparts” (p. 249). The contribution of the study is the detailed information it provides about how students generated their judgments. For example, Butler’s qualitative data analyses revealed that when asked to self-assess in terms of vague or non-specific items, the children often “contextualized the descriptions based on their own experiences, goals, and expectations,” (p. 257) focused on the task at hand, and situated items in the specific task context. Perhaps as a result, the correlation between after-task self-assessment and task performance was generally higher than for generic self-assessment.
Butler (2018) notes that her study enriches our empirical understanding of the processes by which children respond to self-assessment. This is a very promising direction for the field. Similar studies of processing during formative self-assessment of a variety of task types in a classroom context would likely produce significant advances in our understanding of how and why self-assessment influences learning and performance.
Student Perceptions
Fifteen of the studies listed in Table S1 (Supplementary Material) focused on students’ perceptions of self-assessment. The studies of children suggest that they tend to have unsophisticated understandings of its purposes (Harris and Brown, 2013; Bourke, 2016) that might lead to shallow implementation of related processes. In contrast, results from the studies conducted in higher education settings suggested that college and university students understood the function of self-assessment (Ratminingsih et al., 2018) and generally found it to be useful for guiding evaluation and revision (Micán and Medina, 2017), understanding how to take responsibility for learning (Lopez and Kossack, 2007; Bourke, 2014; Ndoye, 2017), prompting them to think more critically and deeply (van Helvoort, 2012; Siow, 2015), applying newfound skills (Murakami et al., 2012), and fostering self-regulated learning by guiding them to set goals, plan, self-monitor and reflect (Wang, 2017).
Not surprisingly, positive perceptions of self-assessment were typically developed by students who actively engaged the formative type by, for example, developing their own criteria for an effective self-assessment response (Bourke, 2014), or using a rubric or checklist to guide their assessments and then revising their work (Huang and Gui, 2015; Wang, 2017). Earlier research suggested that children’s attitudes toward self-assessment can become negative if it is summative (Ross et al., 1998). However, even summative self-assessment was reported by adult learners to be useful in helping them become more critical of their own and others’ writing throughout the course and in subsequent courses (van Helvoort, 2012).
Achievement
Twenty-five of the studies in Table S1 (Supplementary Material) investigated the relation between self-assessment and achievement, including two meta-analyses. Twenty of the 25 clearly employed the formative type. Without exception, those 20 studies, plus the two meta-analyses (Graham et al., 2015; Sanchez et al., 2017) demonstrated a positive association between self-assessment and learning. The meta-analysis conducted by Graham and his colleagues, which included 10 studies, yielded an average weighted effect size of 0.62 on writing quality. The Sanchez et al. meta-analysis revealed that, although 12 of the 44 effect sizes were negative, on average, “students who engaged in self-grading performed better (g = 0.34) on subsequent tests than did students who did not” (p. 1,049).
All but two of the non-meta-analytic studies of achievement in Table S1 (Supplementary Material) were quasi-experimental or experimental, providing relatively rigorous evidence that their treatment groups outperformed their comparison or control groups in terms of everything from writing to dart-throwing, map-making, speaking English, and exams in a wide variety of disciplines. One experiment on summative self-assessment (Miller and Geraci, 2011), in contrast, resulted in no improvements in exam scores, while the other one did (Raaijmakers et al., 2017).
It would be easy to overgeneralize and claim that the question about the effect of self-assessment on learning has been answered, but there are unanswered questions about the key components of effective self-assessment, especially social-emotional components related to power and trust (Andrade and Brown, 2016). The trends are pretty clear, however: it appears that formative forms of self-assessment can promote knowledge and skill development. This is not surprising, given that it involves many of the processes known to support learning, including practice, feedback, revision, and especially the intellectually demanding work of making complex, criteria-referenced judgments (Panadero et al., 2014). Boud (1995a,b) predicted this trend when he noted that many self-assessment processes undermine learning by rushing to judgment, thereby failing to engage students with the standards or criteria for their work.
Self-Regulated Learning
The association between self-assessment and learning has also been explained in terms of self-regulation (Andrade, 2010; Panadero and Alonso-Tapia, 2013; Andrade and Brookhart, 2016, 2019; Panadero et al., 2016b). Self-regulated learning (SRL) occurs when learners set goals and then monitor and manage their thoughts, feelings, and actions to reach those goals. SRL is moderately to highly correlated with achievement (Zimmerman and Schunk, 2011). Research suggests that formative assessment is a potential influence on SRL (Nicol and Macfarlane-Dick, 2006). The 12 studies in Table S1 (Supplementary Material) that focus on SRL demonstrate the recent increase in interest in the relationship between self-assessment and SRL.
Conceptual and practical overlaps between the two fields are abundant. In fact, Brown and Harris (2014) recommend that student self-assessment no longer be treated as an assessment, but as an essential competence for self-regulation. Butler and Winne (1995) introduced the role of self-generated feedback in self-regulation years ago:
[For] all self-regulated activities, feedback is an inherent catalyst. As learners monitor their engagement with tasks, internal feedback is generated by the monitoring process. That feedback describes the nature of outcomes and the qualities of the cognitive processes that led to those states (p. 245).
The outcomes and processes referred to by Butler and Winne are many of the same products and processes I referred to earlier in the definition of self-assessment and in Table 1.
In general, research and practice related to self-assessment has tended to focus on judging the products of student learning, while scholarship on self-regulated learning encompasses both processes and products. The very practical focus of much of the research on self-assessment means it might be playing catch-up, in terms of theory development, with the SRL literature, which is grounded in experimental paradigms from cognitive psychology (de Bruin and van Gog, 2012), while self-assessment research is ahead in terms of implementation (E. Panadero, personal communication, October 21, 2016). One major exception is the work done on Self-regulated Strategy Development (Glaser and Brunstein, 2007; Harris et al., 2008), which has successfully integrated SRL research with classroom practices, including self-assessment, to teach writing to students with special needs.
Nicol and Macfarlane-Dick (2006) have been explicit about the potential for self-assessment practices to support self-regulated learning:
To develop systematically the learner’s capacity for self-regulation, teachers need to create more structured opportunities for self-monitoring and the judging of progression to goals. Self-assessment tasks are an effective way of achieving this, as are activities that encourage reflection on learning progress (p. 207).
The studies of SRL in Table S1 (Supplementary Material) provide encouraging findings regarding the potential role of self-assessment in promoting achievement, self-regulated learning in general, and metacognition and study strategies related to task selection in particular. The studies also represent a solution to the “methodological and theoretical challenges involved in bringing metacognitive research to the real world, using meaningful learning materials” (Koriat, 2012, p. 296).
Future Directions for Research
I agree with (Yan and Brown, 2017) statement that “from a pedagogical perspective, the benefits of self-assessment may come from active engagement in the learning process, rather than by being “veridical” or coinciding with reality, because students’ reflection and metacognitive monitoring lead to improved learning” (p. 1,248). Future research should focus less on accuracy/consistency/veridicality, and more on the precise mechanisms of self-assessment (Butler, 2018).
An important aspect of research on self-assessment that is not explicitly represented in Table S1 (Supplementary Material) is practice, or pedagogy: Under what conditions does self-assessment work best, and how are those conditions influenced by context? Fortunately, the studies listed in the table, as well as others (see especially Andrade and Valtcheva, 2009; Nielsen, 2014; Panadero et al., 2016a), point toward an answer. But we still have questions about how best to scaffold effective formative self-assessment. One area of inquiry is about the characteristics of the task being assessed, and the standards or criteria used by learners during self-assessment.
Influence of Types of Tasks and Standards or Criteria
Type of task or competency assessed seems to matter (e.g., Dolosic, 2018, Nguyen and Foster, 2018), as do the criteria (Yilmaz, 2017), but we do not yet have a comprehensive understanding of how or why. There is some evidence that it is important that the criteria used to self-assess are concrete, task-specific (Butler, 2018), and graduated. For example, Fastre et al. (2010) revealed an association between self-assessment according to task-specific criteria and task performance: In a quasi-experimental study of 39 novice vocational education students studying stoma care, they compared concrete, task-specific criteria (“performance-based criteria”) such as “Introduces herself to the patient” and “Consults the care file for details concerning the stoma” to vaguer, “competence-based criteria” such as “Shows interest, listens actively, shows empathy to the patient” and “Is discrete with sensitive topics.” The performance-based criteria group outperformed the competence-based group on tests of task performance, presumably because “performance-based criteria make it easier to distinguish levels of performance, enabling a step-by-step process of performance improvement” (p. 530).
This finding echoes the results of a study of self-regulated learning by Kitsantas and Zimmerman (2006), who argued that “fine-grained standards can have two key benefits: They can enable learners to be more sensitive to small changes in skill and make more appropriate adaptations in learning strategies” (p. 203). In their study, 70 college students were taught how to throw darts at a target. The purpose of the study was to examine the role of graphing of self-recorded outcomes and self-evaluative standards in learning a motor skill. Students who were provided with graduated self-evaluative standards surpassed “those who were provided with absolute standards or no standards (control) in both motor skill and in motivational beliefs (i.e., self-efficacy, attributions, and self-satisfaction)” (p. 201). Kitsantas and Zimmerman hypothesized that setting high absolute standards would limit a learner’s sensitivity to small improvements in functioning. This hypothesis was supported by the finding that students who set absolute standards reported significantly less awareness of learning progress (and hit the bull’s-eye less often) than students who set graduated standards. “The correlation between the self-evaluation and dart-throwing outcomes measures was extraordinarily high (r = 0.94)” (p. 210). Classroom-based research on specific, graduated self-assessment criteria would be informative.
Cognitive and Affective Mechanisms of Self-Assessment
There are many additional questions about pedagogy, such as the hoped-for investigation mentioned above of the relationship between accuracy in formative self-assessment, students’ subsequent study behaviors, and their learning. There is also a need for research on how to help teachers give students a central role in their learning by creating space for self-assessment (e.g., see Hawe and Parr, 2014), and the complex power dynamics involved in doing so (Tan, 2004, 2009; Taras, 2008; Leach, 2012). However, there is an even more pressing need for investigations into the internal mechanisms experienced by students engaged in assessing their own learning. Angela Lui and I call this the next black box (Lui, 2017).
Black and Wiliam (1998) used the term black box to emphasize the fact that what happened in most classrooms was largely unknown: all we knew was that some inputs (e.g., teachers, resources, standards, and requirements) were fed into the box, and that certain outputs (e.g., more knowledgeable and competent students, acceptable levels of achievement) would follow. But what, they asked, is happening inside, and what new inputs will produce better outputs? Black and Wiliam’s review spawned a great deal of research on formative assessment, some but not all of which suggests a positive relationship with academic achievement (Bennett, 2011; Kingston and Nash, 2011). To better understand why and how the use of formative assessment in general and self-assessment in particular is associated with improvements in academic achievement in some instances but not others, we need research that looks into the next black box: the cognitive and affective mechanisms of students who are engaged in assessment processes (Lui, 2017).
The role of internal mechanisms has been discussed in theory but not yet fully tested. Crooks (1988) argued that the impact of assessment is influenced by students’ interpretation of the tasks and results, and Butler and Winne (1995) theorized that both cognitive and affective processes play a role in determining how feedback is internalized and used to self-regulate learning. Other theoretical frameworks about the internal processes of receiving and responding to feedback have been developed (e.g., Nicol and Macfarlane-Dick, 2006; Draper, 2009; Andrade, 2013; Lipnevich et al., 2016). Yet, Shute (2008) noted in her review of the literature on formative feedback that “despite the plethora of research on the topic, the specific mechanisms relating feedback to learning are still mostly murky, with very few (if any) general conclusions” (p. 156). This area is ripe for research.
More information: Effort Self-Talk Benefits the Mathematics Performance of Children with Negative Competence Beliefs, Child Development (2019). DOI: 10.1111/cdev.13347



{kind=link}