








")


 Extract (6-MSITC) in Healthy Older Adults")
: An In-Depth Exploration into its Thermogenic Role and Social Significance")



Research revealing how over 1300 Android apps are collecting sensitive data even when users have explicitly denied the required permissions.
The research was primarily focused on how app developers abuse multiple ways around to collect location data, phone identifiers, and MAC addresses of their users by exploiting both covert and side channels.
Now, a separate team of cybersecurity researchers has successfully demonstrated a new side-channel attack that could allow malicious apps to eavesdrop on the voice coming out of your smartphone’s loudspeakers without requiring any device permission.
Abusing Android Accelerometer to Capture Loudspeaker Data
Dubbed Spearphone, the newly demonstrated attack takes advantage of a hardware-based motion sensor, called an accelerometer, which comes built into most Android devices and can be unrestrictedly accessed by any app installed on a device even with zero permissions.
An accelerometer is a motion sensor that lets apps monitor the movement of a device, such as tilt, shake, rotation, or swing, by measuring the time rate of change of velocity with respect to magnitude or direction.
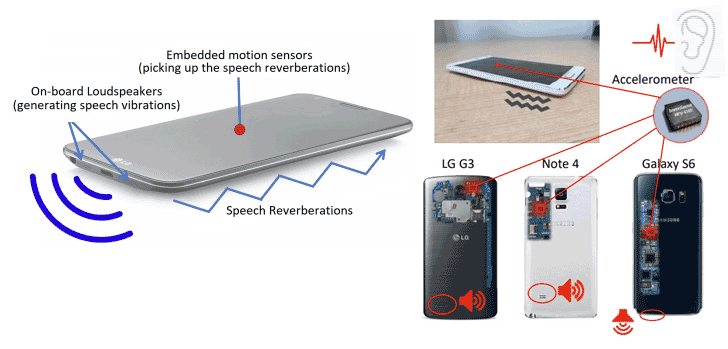
Since the built-in loudspeaker of a smartphone is placed on the same surface as the embedded motion sensors, it produces surface-borne and aerial speech reverberations in the body of the smartphone when loudspeaker mode is enabled.
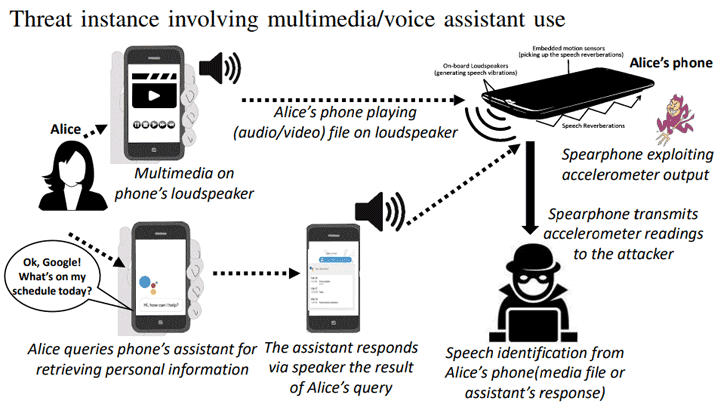
Discovered by a team of security researchers – Abhishek Anand, Chen Wang, Jian Liu, Nitesh Saxena, Yingying Chen – the attack can be triggered when the victim either places a phone or video call on the speaker mode, or attempts to listen to a media file, or interacts with the smartphone assistant.
As a proof-of-concept, researchers created an Android app, which mimics the behavior of a malicious attacker, designed to record speech reverberations using the accelerometer and send captured data back to an attacker-controlled server.
Researchers say the remote attacker could then examine the captured readings, in an offline manner, using signal processing along with “off-the-shelf” machine learning techniques to reconstruct spoken words and extract relevant information about the intended victim.
Spearphone Attack: Spy On Calls, Voice Notes, and Multimedia
According to the researchers, the Spearphone attack can be used to learn about the contents of the audio played by the victim – selected from the device gallery over the Internet, or voice notes received over the instant messaging applications like WhatsApp.
“The proposed attack can eavesdrop on voice calls to compromise the speech privacy of a remote end-user in the call,” the researchers explain.
“Personal information such as social security number, birthday, age, credit card details, banking account details, etc. consist mostly of numerical digits. So, we believe that the limitation of our dataset size should not downplay the perceived threat level of our attack.”
Researchers also tested their attack against phone’s smart voice assistants, including Google Assistant and Samsung Bixby, and successfully captured response (output results) to a user query over the phone’s loudspeaker.
The researchers believe that by using known techniques and tools, their Spearphone attack has “significant value as it can be created by low-profile attackers.”
Besides this, Spearphone attack can also be used to simply determine some other user’s speech characteristics, including gender classification, with over 90% accuracy, and speaker identification, with over 80% accuracy.
“For example, an attacker can learn if a particular individual (a person of interest under surveillance by law enforcement) was in contact with the phone owner at a given time,” the researchers say.
Nitesh Saxena also confirmed that the attack can not be used to capture targeted users’ voice or their surroundings because “that is not strong enough to affect the phone’s motion sensors, especially given the low sampling rates imposed by the OS,” and thus also doesn’t interfere with the accelerometer readings.
For more details, we encourage our readers to head onto the full research paper [PDF], titled “Spearphone: A Speech Privacy Exploit via Accelerometer-Sensed Reverberations from Smartphone Loudspeakers.”
The paper also discussed some possible mitigation techniques that may help prevent such attacks, as well as a few limitations, including low sampling rate and variation in maximum volume and voice quality of different phone that could negatively impact the accelerometer readings.
Research
- BACKGROUND AND RELATED WORK
Motion sensors are a small piece of technology that measure and record a physical, motion-relevant property.
This measure- ment or reading is then utilized by an application for required purposes.
Accelerometers and gyroscopes are the common motion sensors deployed on smartphones. An accelerometer is used to measure movement and orientation and the gyroscope is used to measure angular rotation, across x, y, and z axes.
Motion sensors have been shown prone to acoustic noise particularly at high frequency and power level in [12], [13], [14], which showed that MEMS gyroscopes are susceptible to high power, high frequency noise that contains frequency components in proximity of the resonating frequency of the gyroscope’s proof mass.
This concept of work was further utilized by Son et al. [15] to interfere with the flight control system of a drone using intentional sounds that were produced by a Bluetooth speaker attached to the drones with a sound pressure level of 113dB.
This attack was enough to destabilize one of the target drones used in the experiment due to fluctu- ations in the output of the gyroscope from the interference of the noise near the resonant frequency of the sensor.
The use of motion sensors (gyroscope, in particular) as a microphone to pick up speech signals was first reported by Michalevsky et al. [1].
They showed that the gyroscope sensor in smartphones might be sensitive enough to be affected by speech signals. Since gyroscope sensor in smartphones has a sampling rate of 200Hz, there exists an overlap with the frequency range of human voice especially at the lower end of the spectrum.
In another work done by Zhang et al. [2], it was shown that accelerometer readings could be affected by speech. In particular, they reported that it was possible to detect the voice commands (hotwords) spoken by the user through the accelerometer sensor.
Both [1] and [2] used speech that was produced by either a loudspeaker or a phone speaker to test its effect on the sensors.
The Gyrophone [1] setup tested the impact of speech generated by a loudspeaker (with a subwoofer) on a phone placed on the same surface as the loudspeaker.
AccelWord [2] tested the impact of speech generated by the phone speaker.
We re-investigate both approaches in our work and extend them to other possible scenarios that have not been studied before.
In addition, there are examples of motion sensors leaking information other than speech, thereby compromising user privacy through another class of attacks. Cai et al. [16] used motion sensors to infer keystrokes from virtual keyboards on smartphone’s touchscreen. Using vibration patterns from different parts of the keyboard, they were able to recover more than 70% of the keystrokes.
This work was extended by Owusu et al. [17] by extracting 6-character passwords by logging accelerometer readings during password entry. Xu et al. [18] performed a similar study and were able to extract confidential user input (passwords, phone numbers, credit card details etc.) using motion sensors. In a work similar to [19], Miluzzo et al. [20] showed that it was possible to identify tap location on smartphone’s screen with an accuracy of 90% and english letters could be inferred with an accuracy of 80%.
- MOTION SENSOR DESIGN
Motion sensors in smartphone and other smart devices are implemented as micro-electro-mechanical system (MEMS) that uses miniaturized mechanical (levers, springs, vibrating structures, etc.) and electro-mechanical (resistors, capacitors, inductors, etc.) elements developed using microfabrication.
They are designed to work in coordination to sense and mea- sure the physical properties of their surrounding environment.
MEMS Gyroscope: A gyroscope is a motion-sensing device, based on the principle of conservation of momentum, that can be used to measure angular velocity.
An MEMS gyroscope works on the principle of rotation of vibrating objects or Coriolis effect [21].
This effect causes a deflection to the path of the rotating mass when observed in its rotating reference frame.
MEMS gyroscopes fall in the category of vibrating structure gyroscope as they use a vibrating mass in their design.
The Coriolis effect described above causes the vibrating mass to exert a force that is read from a capacitive sensing structure supporting the vibrating mass.
MEMS Accelerometer: An accelerometer is an electro- mechanical device that can be used to measure gravity and dynamic acceleration such as motion and vibrations.
The basic design of an MEMS accelerometer can be modeled as mass-spring system.
A proof mass (an object of known quantity of mass) is attached to a spring of known spring constant, which in turn is attached to the support structure.
An external acceleration causes the proof mass to move, causing a capacitive change that is measured to provide the acceleration value. It may also be noted that the accelerometer does not measure the rate of change of velocity rather it measures acceleration relative to gravity or free-fall.
- PRELIMINARIES AND ATTACK SCENARIOS
In this section, we discuss some preliminary notions that will be used in our analysis of motion sensor behavior in the presence of speech. We also examine the signal characteristics of speech and the response of motion sensors in the frequency range of the speech. We further look at scenarios that could be potential avenues for executing a side channel attack against speech privacy by exploiting the motion sensors.
- Basic Audio Principles
The fundamental frequency for speech is between 100Hz to 400Hz. The fundamental frequency for a human male speech lies in the range 85Hz-180Hz and for a human female from 165Hz-255Hz.
The fundamental frequency may change while singing where it may range from 60Hz to 1500Hz [22].
The sampling frequency of the MEMS sensors could range up to 8kHz.
For example, the sampling frequency (also referred to as output data rate) in the latest Invensense motion sensor chip MPU9250 is described as 8kHz for the gyroscope and 4kHz for the accelerometer [23].
However, the operating platforms on smartphones often place a limit on the sampling frequency of these devices.
This limit is often implemented in the device driver code and is 200Hz for Android platform [1], [2] in order to prevent battery drain from frequent updates.
Nyquist sampling theorem states that to capture all the information about the signal, sampling frequency should be at least twice the highest frequency contained in the signal.
For the MEMS motion sensors embedded in the smartphones, the sampling frequency is restricted to 200Hz that implies that they can only capture frequencies up to 100Hz.
Hence, the motion sensor may only be able to capture a small range of the human speech in the sub-100Hz frequency range although due to aliasing effect we can expect higher frequency speech to feature in the sub-100Hz range as reported in [1].
- Experimental Attack Scenarios
In order to test the effect of speech on MEMS motion sensors, we conceptualize different scenarios that encompass the intended objective of this work.
There are three factors that should be taken into account in the experiments that affect the behavior of the motion sensors: (1) Source of speech, (2) Medium through which the audio travels, and (3) Pressure level of speech.
- Source of Speech: Speech can be generated through various sources that we broadly classify into two cat- egories: human voices and machine-rendered speech. Human voices could further be broken down into male voices and female voices. Machine-rendered speech in- volves rendering of a human voice through a speaker system. In our experiments, we use (a) a powerful speech generating device like a conventional loudspeaker with subwoofers (that boost low frequency sounds and may induce vibrations), and (b) in-built laptop speakers and smartphone speakers that are less powerful, as possible sources of speech.
- Audio Transfer Medium: To consider the effect of speech on motion sensors, we need to take in account the medium through which an audio signal travels to the motion sensors. The transmission of speech to motion sensors could be through vibrations in the air or vibrations within the surface shared by both the speech generating device and the motion sensors. We test conduction of sound through air and through commonly used surfaces such as wood and plastic.
- Sound Pressure Level: Sound pressure level is an indicator of the loudness of sound and is measured in decibels (db). Louder sounds contain more energy and could have greater effect on the motion sensors. For this reason, we test the sounds at different loudness measured in decibels to correlate loudness with effect on the motion sensors.
We design our scenarios based on the three factors detailed above. The initial setup in our work is similar to the experi- mental setup designed in [1] where the smartphone is placed on a desk with a loudspeaker that emits speech. For human speech, we position a human speaker very close to the desk on which the smartphone is placed to test the potential for capturing human speech.
- Machine-Rendered Speech: We begin by recreating the
scenario reported in Gyrophone [1], where the smartphone is placed on a desk with a loudspeaker (with subwoofer) that emits human speech. The scenario, henceforth referred as “Loudspeaker-Same-Surface”, is depicted in Appendix Fig
1. Here, the phone is in full contact with the surface on which the loudspeaker is placed. As motivated earlier, this scenario can occur in restricted closed door meetings or speeches where the designated speakers are speaking in a microphone and their speech is relayed to the audience through loudspeakers. In this case, the attacker places a smartphone on the same surface as the loudspeaker so that the motion sensors in the smartphone can pick up speech played through the loudspeakers, which are then read by the attacker. The attacker can also utilize a compromised smartphone that the user inadvertently places on the same surface as the sound source.
An additional scenario for machine-rendered speech would be placing the smartphone containing the motion sensors on a different surface than the speech rendering device.
We implement this scenario, called “Loudspeaker-Different- Surface”, by placing the smartphone on a different surface than the loudspeaker, as depicted in Appendix Figure 2.
Additional scenarios are tested with laptop speakers “Laptop- Same-Surface”. Laptop speaker scenario can occur when the victim is in, for instance, a VoIP call using his/her laptop with its speakers turned on and put down their smartphone near the laptop. We also test smartphone speaker scenario “Phone-Different-Surface” similar to [2] where the speech is rendered through smartphone speakers and picked up by another smartphone placed in its vicinity.
- Human Speech: In all the previously described scenar- ios, the speech used for measuring the response of the motion sensors is being produced by a loudspeaker. Such machine- rendered speech is different from a human speaker in the sense that a loudspeaker can effectively produce a louder speech than a human can. In order to achieve commonly occurring setup, we design a human speaker scenario where a human speaker speaks directly in the smartphone. This setup mimics a scenario where an attacker may eavesdrop on user’s conversation that takes place on or near their smartphone.
In our experiment, we place the phone on a stationary and isolated surface and ask the test subjects to speak into the smartphone. In one scenario, we ask the human subjects to speak in normal voice (“Human-Normal”) and in the other scenario, we ask them to speak as loud as possible (“Human- Loud”) to maximize the effect of speech (if any) on the motion sensors.
- Signal Analysis Methodology: We developed a two- pronged approach to analyze the effect of speech on the motion sensors. In the initial step, we analyze the motion sensor signal in the frequency domain to look for footprints indicating the presence of speech. If the frequency spectrum shows such an evidence, techniques proposed in [1] and [2] could be used to further classify, recognize or reconstruct the speech signal (such classification is beyond the scope of our paper). If the frequency spectrum is unable to show any evidence, we analyze the signal in time domain to look for effects of speech on motion sensors.
Frequency Domain Analysis: To perform the analysis of the motion sensor behavior in presence of speech in the frequency domain, we record speech through the motion sensors and plot the spectrum of the observed signal.
We perform similar proce- dure as prescribed in [1] by playing a 280Hz tone and a multi- tone (consisting of signals having frequencies between 130Hz and 200Hz) from a device for machine-rendered scenarios.
Since motion sensors have low sampling rates, the observed frequency range is limited. In case of gyroscope, the sampling rate is 200Hz so observable frequency is limited to 100Hz. Due to this behavior, we depend upon aliasing effect to detect the effects due to the played sound on the spectrum at sub- 100Hz frequency range [1].
Time Domain Analysis: In order to measure the
presence of
a noticeable response of the motion sensors against speech in time domain, we need to compare their behavior in the presence and absence of speech signals.
This requires creating two (nearly) identical environments for all the previously de- scribed scenarios where one environment contains speech and the other environment is devoid of speech.
Placing identical sensors in both environments and measuring their response would accurately determine the susceptibility of motion sen- sors against human speech. However, creating acoustically identical environments may prove to be a challenge where all parameters like temperature, humidity, pressure, the material and the design of the environment need to be same and constant throughout the experimental phase.
An anechoic chamber as suggested in [1] may be deemed suitable for creating identical acoustic chambers.
However, in our work, we circumvent this challenge by performing the normal experiment with human speech immediately fol- lowed by a control experiment with no speech, under normal room conditions (in a quiet laboratory room inside university building).
If we do not allow any sudden and significant interference (acoustic or vibration) in the environment between the experiments, it should be safe to assume that all the environment variables remained almost constant throughout the experiment.
This means the experiments were performed under almost similar conditions and the only noticeable effect should be due to the human speech.
In that case, our setup would be emulating the behavior of nearly identical acoustic environments, as described previously.
We recorded and analyzed the sensor readings looking for noticeable effect such as increase in sensor values that may indicate towards presence of speech. We observed multiples audio samples from TIDigits speech corpus[24] and concluded that the pronunciation of a single digit in the corpus took no more than one second.
The effect of speech on motion sensor readings lasts for around 0.5 seconds meaning for a sampling frequency of 200Hz (as deployed by the motion sensors), this time duration equates to 100 samples.
Thus, we windowed each recorded sample using a window size of 100 samples with an overlap of 50 samples.
In each window, we calculated the maximum range achieved by the sensor, which will give us an idea of the disturbance in the readings.
If speech signal were strong enough to affect the sensors, the readings would be much higher thereby producing a higher range (due to sensors recording more motion data) when compared to sensor value ranges observed in a relatively silent environment.
Sensor Reading Application: We used the Android application available at [25] to capture sensor readings but modified the source code to include accelerometer sensor readings.
- SENSOR BEHAVIOR UNDER QUIET CONDITIONS Before studying the effect of speech on motion sensors, we observe motion sensors’ behavior under ambient conditions, i.e., in a quiet environment. This behavior can then be compared against the behavior of motion sensors under the influence of speech with the assumption that the acoustic environment remains the same.




{kind=link}